UMBC has been using a custom IDMS system since 2002. Over the years it has grown quite extensive, so replacing it is no small matter. We are looking to use MidPoint as a replacement, and my desire is to avoid a large "switchover date". Instead replacing pieces as they become available. To this end I've decided to start with two functions that are relatively isolated and can also be greatly improved by transitioning to MidPoint. The first is UMBC's account provisioning engine. It seems like a good candidate because it is a currently a single standalone process that could use a rewrite to improve its robustness, logging, and modularity.
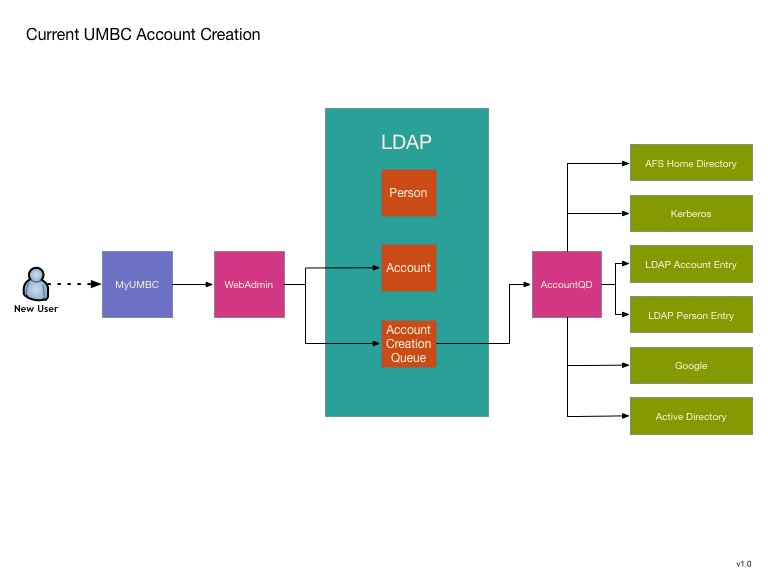
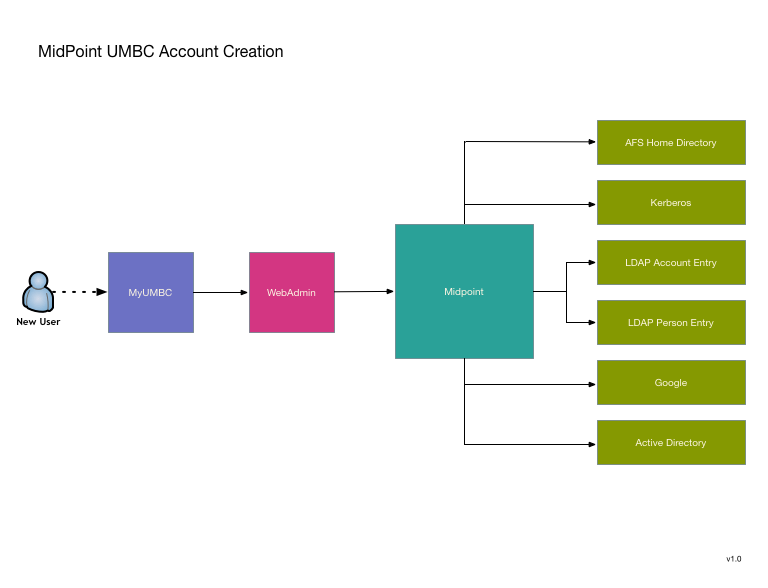
Transitioning to MidPoint will not substantially change the model, but will offer allow MidPoint's improvements without reliance on major shim code writing that will have to be replaced as we do additional migrations toward total conversion to MidPoint.
The second function that appears to be a good candidate is UMBC's guest account request system. Currently there really isn't one, or rather there are four completely different systems that combine to cover most of the use cases. These could all use improvement and I think that a unified conversion to MidPoint will allow improvements as well as a workflow simplification.
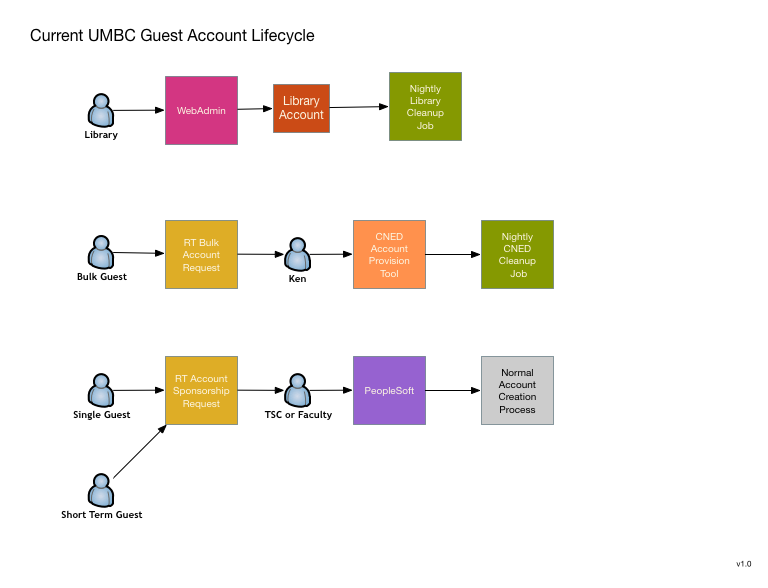

This is primarily a request system, although some of the current systems do perform their own provisioning and de-provisinioning within a limited scope. It is still unclear to what extend MidPoint can be used as an end user request or approver UI. If it is unable to be used in this way, I'm looking at using possibly using CoManange to perform these UI functions rather than writing something myself.
We had four attendees at the Face2Face Meeting, Randy Miotke and Jeff Ruch are our technical team members, Scott Baily our campus lead, and Dave Hoffman from project management. Our entire group found the experience very worthwhile and came back with a lot of positive feedback.
Our technical team, through discussion and presentations, are now looking to use COmanage as the source of record for the external to CSU population and then provision to midPoint registry. We will use midPoint as the primary entity registry and leverage its provisioning capabilities. They both appreciated the Grouper office hours that were provided as several items that they were struggling with were resolved on-site.
From a project management perspective, developing networking with other institutions and discussing common issues was important. Moving forward, collaboration around how to better engage and work with vendors is something that needs to continue. Along with our technical team, he found that discussion regarding implementation plans around Midpoint and sharing of project plans will be invaluable as we begin looking at this process.
Our team at CSU is in the final stages of implementing COmanage for use as an entity registry with account linking capabilities for use with our department of University Advancement’s Donor Connect system. Here’s how it will work:
A user will go to the Advancement website to access the Donor Connect system; this is our first service provider where we will be implementing this process and there is interest from other departments and system for future expansion. The user will be given options of logging in with the CSU Identity Provider or if the user is not affiliated with CSU another discovery service like Google, Facebook, MSN, etc. Once they select the system they prefer, they will be redirected to that site for authentication. Upon successful login to that system and permission has been granted to share account information with the service provider the Social to SAML gateway will route them back to the Donor Connect page.
At this point, our system will look for a match in our LDAP directory; if there is no match, the user will be put through a verification process. Once they have been verified their information will be logged in COmanage. If the user is already affiliated with CSU they will be in the registry from the data load from our internal HR and Student systems. We will then have both internal and external records in the COmanage Registry.
It will create a unique ID that ties multiple accounts to one person for a quicker authorization process for future access. There is a provisioning process set up to send COmanage person and identity data to the LDAP directory in order for it to be logged and a match to be found the next time a user logs in. There is also a provision in Grouper that sends group data which is also pulled from our internal CSU systems to the LDAP directory.
As of today, person data from CSU systems has been loaded into COmanage and group data has been loaded into Grouper. COmanage and LDAP have production instances in place and the Grouper production instance is being finalized based on deployment guidelines. After this project launches our team will look at containerized versions.

Several years ago, Colorado School of Mines was (I would expect) like many in the Internet2 community – we were aware of efforts around something called TIER, and it had to do with Trust and Identity.But we had a vendor solution around identity and access management that served us (relatively) well, we were members of InCommon, relied on Shibboleth, and we didn’t quite understand where TIER fit in. At some point we even became aware that there were member institutions investing time (and money!) into this effort – but again, it was something on the radar – something that we would pay more attention to “someday”. That day came in mid-2017, when it became clear that we faced the unenviable task of replacing our vendor IAM solution. As one option, we reached out to Internet2 and inquired about TIER, and about what it might take to become a part of the investor program. As luck (would continue) to have it, we were told the initial investor program was coming to a close. However, the inquiry would prove serendipitous, as we were told there was a new opportunity that would soon be announced – the TIER Campus Success Program.
As we learned more about the goals of the Success Program – and its core approach built on the collaboration of other institutions with a common need and goal, our local IAM architect was sold. We are a (relatively) small central IT organization that is known (as my predecessor noted) for “fighting above our weight class”. The thought of being in the ring with others who shared our need, had similar goals, and was working alongside us in those efforts was a reassuring one. As it turned out, we were fortunate to be accepted into the program and joined nine other institutions in this collaborative effort.
Adoption and implementation of the TIER framework at Mines is appealing from several perspectives. First, it provides a potential solution (albeit with significant effort) to a problem that we were facing with no easy, cheap, or fast solutions (nor likely even two of the three). Second, the path to success is via collaboration with Internet2 and other higher ed institutions – some more like us, others not so much like us – but who all share a common need and an interest in a community-built, open-source, IAM solution. Finally, it affords an opportunity to be an active participant in and contribute to the development of what will hopefully come a broadly adopted R&E solution.
There are days I acknowledge that going this route (vs implementing another vendor solution) is a gamble – but I'd like to think it is a calculated one. We’re not in this effort alone – that’s one great thing about the CSP approach. We’re in it with other institutions that have a stake in the success of TIER – and with access to and the support of an incredible group of architects and developers within I2 that are committed to the success of all of us. Internet2 has a history of creating an environment of facilitation, collaboration, and partnership that leads to the development of some indisputably key solutions for the national and international R&E community. I believe TIER has the potential to be another of those solutions.
I like to think we jumped in with our eyes wide open, but it’s impossible to see where all the landmines (or sharks?) may be hidden. We’ll certainly encounter those – but challenges, frustrations, and compromises exist in pretty much any solution. Continuing the metaphor of “jumping in”, I could say things are “going swimmingly”, and that we don’t appear to be “in over our head”, or even “Come on in! The water’s fine!” Or... perhaps not.
We’re giving it our best – and we’ll let you know how it goes.
UMBC’s use of Shibboleth dates to the mid-2000s, when we ran Shibboleth Identity Provider version 1. Our first SAML integration went live circa 2007. We upgraded to IdP v2.0 (and SAML 2.0) in 2010, and IdP v3.0 in 2015.
UMBC has had some form of web single sign-on since 2000, when we launched a home-grown SSO service, called WebAuth, which functions similarly to CAS. Old habits die hard, and in fact, we’re still running the WebAuth service today. Several important web applications continue to rely on it, and it handles front-end authentication for the IdP (via the external authentication plugin). Our long-term goal is to move off WebAuth, and use the Shibboleth IdP exclusively for both authentication and authorization. However, that is not going to happen in the immediate future, so for now, we need to find a way for WebAuth to coexist with the TIER version of the Shibboleth IdP. Currently, they both reside on the same server, with Apache running the front-end AuthN system and proxying requests to the IdP using mod_proxy_http.
Why go to TIER in the first place? Well, it will be a big win for us operationally. Our current setup consists of three VMs behind a load balancer, each running identical configurations of the IdP and WebAuth. The IdP administrator (me) handles operational aspects of the identity provider, including configuration, customization, and upgrades. A separate unit within our division handles lower-level system administration of the VMs themselves, including patching, backups, and security incident response. In general, this division of responsibilities works well; however, there’s currently no mechanism in place for maintaining a consistent configuration across all three load-balanced nodes. Whenever I have to make a change (e.g. to add an attribute release rule, or load metadata for a new relying party) I have to manually propagate the change to each of the servers. It’s tedious and error-prone, and leads to inconsistencies. For example, if one of the VMs is down at the time I make the change, and later comes back up, it will have an older version of the IdP configuration until I manually intervene. While the system administration group has methods in place to facilitate replication, I’m not up to speed on the system they use; and conversely, they’re not familiar enough with the IdP to handle this on their end.
TIER, and the containerization model, promise to make things better for us. Having no real-world experience running Docker containers in production, we still have a significant learning curve ahead of us; however, I think switching from our existing system to a DevOps model will eventually pay dividends. Just to name a single example: replication will be a lot easier, as we’ll have a single “master” copy of the IdP configuration that we’ll use to generate as many running containers as we need, each behind a (yet-to-be-determined) load-balancing mechanism. Also, synchronization is no longer an issue, as older containers can just be spun down and replaced with new containers.
In my next entry, I’ll go into more detail about how we plan to migrate from our existing IdP configuration to a TIER DevOps model.
From University of Michigan
Before containerizing Grouper I thought I was a fairly-well seasoned identity and access management engineer. (Because I’m a big guy my friends might say I’m well-marbled, but that’s another story.)
So when I approached the installation of containerized Grouper I thought I should be able to knock it out in a couple of weeks.
Boy, was I wrong!
I was completely new to containerization. To further complicate matters, containerized Grouper had been created for use with Docker, yet the University of Michigan’s platform of choice for containerization is OpenShift.
Working with our local container gurus I had to get into the “container mindset”: nothing specific about the environment should be in the container itself. Control everything through environment variables and secrets. I also had to tease apart the differences between Docker and OpenShift.
It was maddening.
It took me a month to develop a process to “bake” into a container the stuff that the Docker compose functionality does automatically.
Once I finally built the images and deployed them to OpenShift successfully, I felt immense pride. However, as pride does, it goeth before the fall.
Disappointingly, containerized Grouper still didn’t work. I was under the misapprehension that once I deployed the images to OpenShift, Grouper would magically open up, much like the scene in the movie The Davinci Code when Robert Langdon (Tom Hanks) and Sophie Neveu (Audrey Tautou) enter the code to retrieve the cryptex. Unlike them, I was left with disappointment, frustration, and sadness.
It turns out that simply running kompose convert (which I had stumbled upon, miraculously) and importing all the deployment configurations, routes, and services into OpenShift would not do the trick. I had to get into the nitty-gritty of OpenShift’s routing and services architecture myself.
It was a cold January day when I finally configured the routes and services in some meaningful way and was able to retrieve the Grouper service provider’s metadata. Progress! And about an hour later, I was finally able to see the Grouper UI, albeit over an unencrypted connection.
To actually log into Grouper successfully, though, would take me another three weeks. I eventually discovered that I had inadvertently shot my own foot, then hit it with a hammer a couple of times: when I had first started working on Grouper, I had modified the services.xml files in an inconsistent and absurd manner.
Once I edited them consistently I was finally able to log into Grouper! Oh joy! Oh bliss!
But never one to rest on my laurels I felt compelled to move forward. Next: implement end-to-end SSL. As it turns out, the solution to SSL was a checkbox and a pull-down menu. To get to the correct combination of clicks, though, took another two weeks.
What’s next? In the next two weeks I hope to have containerized Grouper pointing to our development LDAP and MySQL servers.
What have I learned from containerized Grouper so far?
Despite my advanced old age, I can still learn, albeit it seems a bit more slowly.
Do not take new technologies for granted.
Even though the technology may be new, there are probably still parts of it which function similarly to technologies with which I am very familiar.
Be patient. Chunk what you hope to accomplish into meaningful spoonfuls so as to not get frustrated.
For the interested (or morbidly curious), I am putting together a run book of my travails. It should be available soon.
In conclusion, may all your Grouper pods have a status of Active forevermore!
In 2011, Mines started on a project to replace an epic mess of shell, Perl, C, C++, Python, and a few dozen other odd tools that implemented Mines User Database or UDB for short. In March of 2015, Mines migrated to vendor provided identity and access management solution. The vendor solution had a number of useful features for both administrators and users, including self-service password management. For several reasons, Mines is now faced with replacing its existing vendor solution.
Mines joined InCommon and began utilizing Shibboleth in 2013 and watched with interest as the TIER project got started. Mostly we were interested in Grouper. During the spring / summer of 2017, a number of factors motivated the need to identify a new IAM solution, we were excited to hear about the new I2 Campus Success Program.
Over the past several months, we have been reading up on midPoint and developing a project plan to deploy both midPoint and Grouper. There are quite a few differences between midPoint and the entity registry of the vendor solution. Over the next several months we will be describing those differences and how we intend to get around them.
Prior to our participation in the TIER Campus Success Program, the University of Illinois Identity and Access Management team had been working to deploy Grouper as a campus-wide authorization solution, branded locally as "Authorization Manager", or "AuthMan" for short. AuthMan was marketed on our campus as a solution for centrally managing authorization policies and quickly drew the interest of departments and service/application owners alike. In addition to work on Grouper, our Shibboleth IdP was slated to move to the cloud as part of a cloud-first initiative to migrate many of our central IT services to Amazon Web Services. Our team decided to shift gears with Grouper and deploy it in Amazon Web Services as well to align with this cloud-first initiative. This created a bit of a reset in the project, as we had a new deployment model and process.
In addition to deploying these two services in the cloud, we are also working on migrating our primary LDAP infrastructure to the Active Directory. The University of Illinois has many applications behind Shib, but our Shib IdPs have been using a secondary LDAP as its data source due to Active Directory constraints. Because of the cloud-first initiative and continuing work to consolidate redundant services, we're also working on making the AD our authoritative source of data for both Shib and Grouper. This requires some schema and policy updates to our AD to accommodate FERPA-suppressed users as well as making sure all necessary attributes are correctly mapped in AD.
Over the past month, we've been working on migrating our Shib IdPs to a dockerized TIER package hosted in Amazon Web Services, and have developed a plan to implement shadow attributes in AD to handle FERPA-suppressed users. We needed to resolve some logging dependencies with Shib, and we've used Splunk as the solution. In addition, the AD schema changes are slated for early spring. We're also preparing a dockerized Grouper TIER image for deployment in Amazon Web Services. We are looking forward to working with peer institutions to help us "get over the hump" of learning Grouper and sharing our own experiences with deploying on AWS.
At Georgia Tech, I am part of the Identity and Access Management team and we chose to implement Grouper in Docker as part of the Campus Success Program. It was a natural fit for us as we were already in the middle of a project that was our first foray into making Grouper available to campus. Our Campus Services IT department needed an easy way to manage groups for a Door Access project. Grouper handles this nicely and is easily extensible using Grouper Web Services. As an added twist to our first real Grouper project, we decided to run Grouper in Docker as a way to facilitate development and testing as well as make Grouper as cloud-ready as possible in case we decide to migrate to AWS in the future.
As part of the Door Management project, in addition to granting some admin Grouper access to the Campus Services team for the Grouper UI, we wanted to make it easy for them to be able to build their own custom web ui for interacting with Grouper since their functional end-users may not want to use Grouper directly. At Georgia Tech, we have a custom API framework called BuzzAPI that we use to give developers limited access to internal data. We wrote BuzzAPI wrappers on top of Grouper's Web Services in order to take advantage of the security features and load balancing built in to Buzzapi. With these API's, Campus Services was able to build their own UI to visualize and manipulate their Door Access groups in Grouper.
As we continued to work with Campus Services, they came up with additional uses of Grouper that would help them in other projects. We are using the Grouper Loader to bring in groups from our PeopleSoft system which are then used as reference groups for Grouper groups maintained by Campus Services. Membership in these groups determine which employees are required to take certain training courses in our Learning Management system. The groups in Grouper are provisioned to entitlements in LDAP which can be easily read by the LMS. Campus Services has also started using Grouper to centrally manage groups for their own internal applications that don't have good grouping built in like a Git based wiki system for their documentation.
So far, I feel that our initial exploration into what Grouper has to offer has provided fruit in the form of useful features that fit the needs of our customers from other IT areas on campus. As we learn more about Grouper and continue to improve our Docker architecture, we will expand the use of Grouper to the wider campus. It is my hope that the Campus Success Program will help with that as well as be a good arena to gain feedback and share successes.
From University of Michigan
There is an idea in psychology, often referred to as Maslow's Hammer, that describes the over-reliance on a specific tool. The basic gist is "In the land of the hammer, every problem is a nail.". And we, my friends, find ourselves in the land of the hammer.
For well over a decade, U-M has granted users the ability to create and manage their own groups in our LDAP directory with few restrictions. Groups names have to be long enough as to not overlap with the username namespace. Anyone with a valid username and password can create groups, which includes the 66% of our people registry whose only role is alumni.
For a period of time that was enough; users wanted only to manage email groups and they were happy. Needs change over time. Services evolved needing authorization and provisioning solutions. Resourceful users who needed to provision these services began to create and leverage groups in our LDAP directory as access control groups. Happy hour email groups were suddenly being used fulfill a variety of purposes for which they were not intended nor particularly well suited to.
Today there are over 85,000 groups in our LDAP directory. Group usage continues to grow and use cases continue to increase in complexity. We need to retool group organization and management - especially around access control. We want provide a better tool for campus to easily access and use commonly needed groups like departmental groups. We want these departmental groups to be automatically derived from institutional data instead of manually maintained. We would like to empower people responsible for an access group to tweak them as needed with include/exclude functionality. We would like to be able to accurately identify which groups are used for what and efficiently sync them to appropriate environments for provisioning. We want to monitor groups provisioning higher risk access as well as keep better records of group changes by whom/what, when and how.
‘Tis the season for wish lists.

Before the Campus Success Program, we (UMBC) had previously installed Grouper and created a few sample groups. We have been able to pull data from our various Peoplesoft systems into Grouper, creating reference groups, as a proof of concept. We’ve created two types of groups. Our first use-case was to create a group to give access to Lynda.com. Our contract stated we could give access anyone that met one of the following criteria: ART majors, a student taking an ART class and faculty teaching an ART class. We created the three groups, based on select statements within Peoplesoft and then combined the three into a group we called Lynda.com Access. Our web SSO solution checked to make sure, when someone logs into Lynda.com, that they are a member of the Lynda.com Access group. Our second use-case (still a work on progress) was/is to create a Grouper group that contained part-time faculty members. Our Peoplesoft HR SME gave us a big select statement to pull just that population, based on a number of Peoplesoft tables. We directly loaded that into a single Grouper group. The end goal is to replicate this group into Google apps allowing the Faculty Development Center to target part-time faculty members with emails, calendar notices and file sharing.
So, where does the Campus Success Program come in? We wanted to be part of a cohort of other institutions that were in the same boat - New or mostly new to Grouper and be able to work through issues together. Having access to the Grouper development team will also allow us to have answered for us some of the issues that naturally creep up during a new implementation.
Our Grouper project for Campus Success is to make use of the delivered TIER Docker containers. This will greatly speed up Grouper deployment and upgrades. Down the road, we will look to moving to AWS and make use of Kubernetes for automated resource provisioning. Our second goal is to be able to automatically provision and manage Google groups via membership in Grouper groups. These could be groups provisioned for each class, so BIOL 100 in Spring 2018 would have a corresponding Google group. Also, clubs and organizations would have a Google group provisioned based on membership in one of our campus portal organization groups.
We are early on in the project, but feel we are making decent progress. We’ve been able to successfully install and run the TIER Docker container. It was rather easy to setup but we had some issues with the Shibboleth integration. Thankfully that was resolved once we realized that our Puppet implementation was regularly clobbering our IP tables. Just this week we were able to use the Grouper to Google connector, written by Unicon, to mirror our first Grouper group to Google. Next we need to figure out what that really means in the way of user management. When a member of the Grouper group is removed, what happens in Google? Who owns the Google group? What sort of user management rights do they have? All good questions that we now need to work through.
Before we get too far along in the project, we will have to better understand group naming and organization within Grouper. At this point we feel that we are randomly throwing groups into Grouper. The Grouper deployment guide gives guidance for organization and naming. This will be a great resource. We plan on working closely with other Campus Success program participants to see their naming and organization strategies as well.
Stay tuned...
As the newest campus in the University of California system and the first US research university built in the 21st century, it's hard to imagine such a new institution grappling with the effects of an aging infrastructure and identity platform. The world was a different place in the early 2000s when UC Merced was emerging from a former golf course in California's San Joaquin valley - resources and budgets were (relatively) plentiful, Sun Microsystems was throwing dirt-cheap hardware and software at higher-ed institutions across the country, and "the cloud" was still a weather phenomenon rarely seen during the summer in interior California. UC Merced, like many institutions at the time, invested heavily in local computing capacity with racks of purple computers running Oracle databases, Sun Identity Manager, and Netscape iPlanet Sun ONE Sun Java System Directory Server.
Time marched on, budgets got lean, and Oracle swallowed Sun, leaving UC Merced with no clear path forward to turn its purple data center into something that could continue to support the needs of a rapidly growing research university. Over the years, various efforts to replace the identity management system sputtered and stalled, hardware continued to age, and support for Sun's Identity Manager dried up. Sensing an opportunity to right the ship and contribute to the community at large, UC Merced became a TIER investor campus in 2015 and developed a multi-year IAM roadmap with the ultimate goal of adopting TIER.
Work on an interim solution set off immediately, converting ~10,000 lines of Waveset XPRESS business logic code to Java and retiring the Sun Identity Manager for a homegrown, interim solution. A front-end web application was created in Angular for account management and self-service. Through participation in the TIER Campus Success Program, UC Merced hopes to build on that momentum and replace our interim solutions with midPoint and Grouper.
UC Merced has been working on project planning and securing the resources and talent necessary to pivot towards TIER, containerized apps, and the devops model. To that end, all of you devops engineers looking for an exciting opportunity in the UC system can contact me directly! Our identity and operations teams have been heavily impacted by another project, replacing the University of California's 35+ year old payroll system. Work on that project wraps up this month and the team is looking forward to making significant progress on midPoint and Grouper in 2018.
More and more, people outside of the defined CSU member population need access to a limited set of protected campus resources. Two of our departments, Advancement & the Registrar’s Office, requested the capability to allow former students and donors to use a social identity for authentication into their systems for a variety of reasons. Student user IDs that allow access to online systems, expire one year after graduation. Past students with expired IDs sometimes need online access to records, transcripts, etc. Donors may have never had a university ID. Advancement maintains a system to connect with alumni and donors, which also facilitates giving to the university.
These needs kicked off our team’s goal of implementing COmanage for use as an entity registry with account linking capabilities. The COmanage registry will supply a unique CSU identifier for internal and external populations, which can be referenced by consuming services. The vision is for any CSU service using an external authentication to reference a unique university ID for authorization purposes.
At this point, our team at CSU has put an instance of COmanage into production and we plan to populate CSU accounts soon in order to create the registry IDs. We will also look to implement a test Docker version when available.
Grouper is in production and working well. Our team is evaluating its current structure based on the recently released Grouper deployment guidelines, making sure our structure and the guidelines align properly. The first production LDAP directory, which will support provisioning from Grouper, has been created. We will be bringing up other production nodes and implementing replication in our next steps.
Our team continues to work hard on the development and implementation of these programs and are confident in the process moving forward with no foreseen roadblocks at this point. In the long term, we will be looking to containerize Grouper and COmanage through Docker, as well as review midPoint and how it may fit in at our institution.
Since this is our first foray into running containerized applications, we wanted to explore as many options as we could to find the right fit for our needs, available resources, and comfort level. We want something that we can play with and develop on-premise but will allow for us to migrate into the cloud easily should the opportunity become available.
To that end, we came up with an initial list of possible options: Docker Swarm, Rancher, Kubernetes, OpenShift Origin, and Tectonic. Tectonic was a non-starter; their licensing and installation requirements were not a good fit. Docker Swarm, while being the standard currently used by TIER, was also ruled out due to the lack of a UI for management and the inability to scale up in a non-disruptive manner. Vanilla Kubernetes appeared to require more configuration than the others to get up and running. That left us with Rancher and OpenShift Origin.
We went with Rancher first for its ability to support multiple isolated container orchestration frameworks, including Kubernetes and its own native orchestrator, Cattle. (Besides, this is Texas; ranching is in our blood.) OpenShift Origin was still using Kubernetes v1.6, and there were concerns about how long it would take RedHat (our campus OS distribution of choice) to release updated versions. Rancher also supports easily adding hosts or nodes regardless of the orchestrator via a web front-end that natively supports AWS EC2 and Digital Ocean.
The Cattle orchestrator was initially more attractive because it supports the ability to use the Docker Compose file format and everything can be done within the UI. However we were dissuaded by the lack of auto-scaling and the fact that Secrets support is still experimental. On top of that, it seemed clear that the Rancher project was moving on; Rancher 2.0 was just announced, and it is using Kubernetes as its default orchestrator.
Eager to get something going, we tried setting up the Rancher 2.0 Tech Preview. It was immediately clear that the preview was really just a preview. It's lacking in very basic functionality (authentication, anyone?) So we dropped back down to Rancher 1.6 using Kubernetes as the default orchestrator in the hopes that as 2.0 becomes more viable the transition will be smoother.
We tested and enjoyed working with Kubernetes. We tried out running containers of a few basic applications and explored the auto-scaling features. Things were going great until we hit a wall trying to build an image. We spent some time troubleshooting the issue. It turns out the development VM infrastructure we were given to work with had some I/O constraints that didn't play at all nicely with the overlay2 filesystem. Reads and writes were too slow to perform part of the Dockerfile build for the application we were trying to containerize. We made note of the issue and continued our testing with less I/O intensive applications for now.
After a while, it started to become clear that while Kubernetes was enjoyable to work with, Kubernetes under Rancher 1.6 is less so. We found that in our setup we were having to drop down into the default Kubernetes UI from within the Rancher UI to get tasks done more often than not. Most irritating was the load balancing configuration, which necessitated backing out of the Kubernetes UI to create the config with the Rancher UI and then dropping down into the Kubernetes UI again to configure the nodes. We have hopes that with the focus on Kubernetes for Rancher 2.0 these problems will be mitigated.
So now it's time to try out OpenShift Origin. We're currently waiting for more resources to spin up a dev environment to play with it and see how it compares. Stay tuned!
Assumptions
Create a variable file in group_vars/---midpoint: use_apache_ssl: false