Jump to:
| Table of Contents | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Query instead of "download"
| title | A new Metadata Service is here! |
|---|
The new InCommon Metadata Distribution Service
,is based on the Metadata Query (MDQ) protocol
, is now available as a Release Candidate.
This new service supports realtime per-entity metadata query.It eliminates the need for a metadata
consumersconsumer to
loaddownload the entire metadata aggregate
and saves a ton of system resources and. It significantly reduces system resource overhead and reduces start up time.
InCommon will transition to this new service in the coming months. To begin working with itThere is no more need to download the entire metadata aggregate.
To retrieve metadata using the MDQ-based Metadata Service, visit the new InCommon Metadata Service Wiki.
The InCommon Federation prepares four metadata aggregate for download. Before downloading for the first time, read the Consume InCommon metadata topic to understand best practices and learn to configure software to consume the InCommon metadata.
Download locations
The InCommon Federation metadata aggregates at the following permanent HTTP locations. See Types of metadata aggregates for additional information.
Main metadata aggregate
http://md.incommon.org/InCommon/InCommon-metadata.xml
Fallback (usually identical to the main aggregate, except when we are making schema changes) metadata aggregate
http://md.incommon.org/InCommon/InCommon-metadata-fallback.xml
Preview metadata aggregate
http://md.incommon.org/InCommon/InCommon-metadata-preview.xml
For service providers, an IdP-only metadata aggregate
http://md.incommon.org/InCommon/InCommon-metadata-idp-only.xml
Simulating the legacy style metadata aggregate
Simulating the legacy aggregate
See Retrieving metadata aggregate with MDQ.
If you previously (before 2020) downloaded the InCommon metadata aggregate and cannot switch over to querying individual entities using the MDQ protocol, the new Metadata Service provides an aggregate endpoint to simulate the legacy InCommon metadata aggregate. The aggregate endpoint is:
| Code Block | ||||
|---|---|---|---|---|
| ||||
https://mdq.incommon.org/entities |
IMPORTANT: the new InCommon Metadata Service has a different signing key from the legacy service. If you had configured your service with the legacy key, make sure to update the metadata signing key. See obtain an authentic copy of the InCommon metadata signing certificate.
Retrieving the IdP-only aggregate
See Retrieving metadata aggregate with MDQ.
InCommon produces an metadata aggregate containing only IdP entities. It enable discovery services to retrieve/cache list of identity providers for display purpose.
The InCommon IdP-only aggregate endpoint is :
| Code Block | ||||
|---|---|---|---|---|
| ||||
https://mdq.incommon.org/entities/idps/all |
About the Export-only aggregate
InCommon produces an In addition, we produce one additional export-only aggregate to support inter-federation through the eduGAIN global R&E inter-federation. To learn more, see the Export-only metadata aggregate topic.
About the "Fallback" aggregate
See Using the fallback aggregate.
Verifying the metadata signature
To ensure you are retrieving the properly vetted metadata fro mInCommon, make you You may download the aggregates via their corresponding https:// locations. However: do not depend solely on HTTPS encryption for the security of your metadata downloads. You should always verify the signature on metadata according to the instructions. Do not depend solely on the Consume InCommon metadata page.
Verifying the metadata signature
HTTPS encryption for the security of your metadata downloads. To learn more, see consume-metadata-best-practice.
The InCommon metadata All metadata aggregates are signed using the same metadata signing key and the SHA-256 digest algorithm. To verify the signature on an aggregate, a consumer must obtain an authentic copy of the InCommon metadata signing certificate.
| maxLevel | 2 |
|---|---|
| minLevel | 2 |
| indent | 0px |
| location | top |
| separator | pipe |
Operationally, structural changes to metadata are first introduced into the Preview Aggregate and subsequently synchronized with the Main Aggregate and the Fallback Aggregate, in that order. Time between synchronization events depends on the nature of the structural change.
Metadata consumers choose exactly one of the three aggregates in the pipeline depending on the immediate requirements of their deployment.
| columnAttributes | style="padding-left:1em;text-align:right;,style="padding-left:1em;padding-right:1em;text-align:center;,style="padding-left:1em;padding-right:1em;text-align:center;,style="padding-left:1em;padding-right:1em;text-align:center;",style="padding-left:1em;padding-right:1em;text-align:center;" |
|---|
Retrieving Preview metadata
The "preview" MDQ Service environment allows you to validate your service against upcoming changes to the MDQ Service.
See:
- Locating the preview metadata
- Configure Shibboleth IdP for Preview MDQ environment
- Prefetch an entity with Shibboleth in the Preview MDQ environment
- Configure other software
- Metadata signing key for the Preview environment
Availability
Stability
Reliability
Affinity
Preview Aggregate
24x7
experimental
leading edge
persistent
Main Aggregate
24x7
stable
mainstream
persistent
Fallback Aggregate
24x7
legacy
trailing edge
transient
Multiple metadata aggregates allow InCommon to deploy changes to metadata more quickly, easily, and safely.
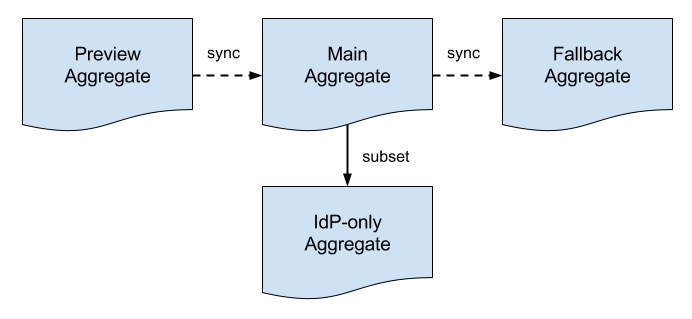
Preview Metadata Aggregate
The Preview Metadata Aggregate helps manage the introduction of potentially breaking changes into InCommon metadata. Before such a change is deployed to the Main Aggregate, it is first introduced in preview mode. Any issues that surface are addressed before the change is synced with the Main Aggregate.
The Preview Aggregate is designed for deployments on the leading edge, such as test and dev deployments. Such deployments are strongly encouraged to consume the Preview Aggregate instead of the Main Aggregate.
| Tip | ||
|---|---|---|
| ||
An important decision point for each deployment is whether to consume the Main Aggregate or the Preview Aggregate. |
Main Metadata Aggregate
In the best possible world, a deployment would configure itself to refresh its metadata store from the Main Metadata Aggregate and that would be the end of it. The problem is that metadata aggregates are brittle by their very nature, that is, a small change to metadata may have unexpected effects downstream. If this happens, a deployment can “fall back” to a previous version of metadata that is known to be backward compatible.
Fallback Metadata Aggregate
The Fallback Metadata Aggregate comes into play when a breaking change is inadvertently introduced into InCommon metadata. When a change is made to the Main Aggregate, and that change breaks a downstream metadata process, an affected deployment can temporarily migrate to the Fallback Aggregate. This gives the deployment time to adjust to the breaking change.
A deployment should consume the Fallback Aggregate only when it has to, that is, when it is unable to consume the Main Aggregate. Consuming the Fallback Aggregate is a temporary measure while a deployment reacts to a breaking change introduced into InCommon metadata. See the article Using the fallback aggregate for more information.
The Fallback Aggregate is transient in the sense that backward compatibility is provided for a limited, predetermined period of time. This forces deployments to adjust to breaking changes to metadata albeit in a controlled environment.
IdP-only Aggregate
This aggregates contains only the IdP entities. It is designed for use by service providers (SP) to streamline operations. SPs have no need to parse the over 5,000 SP entites in the InCommon metadata aggregate. Loading them only wastes system resource and slows systems start up time. See IdP-only metadata aggregate for more information.
Comparing the differences between versions of metadata aggregates
Differences between the various metadata aggregates are recorded and archived daily:
Vertical diff between two consecutive instances of the Main Aggregate
Horizontal diff between the Main Aggregate and the Preview Aggregate
Horizontal diff between the Fallback Aggregate and the Main Aggregate
The vertical diff captures changes to metadata over time. The horizontal diffs record the flow of metadata through the preview-main-fallback pipeline.
To obtain a diff of consecutively published metadata aggregates, visit the InCommon metadata diff history web page. Alternatively, you may requested via email.In this section
| Children Display | ||||
|---|---|---|---|---|
|
Related content
| Content by Label | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Get help
Can't find what you are looking for?
| Button Hyperlink | ||||||||
|---|---|---|---|---|---|---|---|---|
|