Federation Without Boundaries
What is interfederation? The goal of interfederation is to dissolve federation boundaries. If and when that goal is achieved, the term “interfederation” will simply disappear from use since “interfederation” will be indistinguishable from what we now call “federation.” In other words, interfederation is the new federation!
We’ve seen this happen before. Once upon a time, the terms “internet,” “intranet,” and “extranet” were widely used. As network boundaries blurred, that distinction mostly vanished, and with it the old terminology simply collapsed onto a single term: internet (with or without a capital “I” depending on your point of view). Exactly the same phenomenon will happen with the terms “federation” and “interfederation.” The latter is merely a short-term manifestation of a maturing federated model.
Interfederation is still very much in its infant stage. At this point in its evolution, the focus is on metadata aggregation. There are two well-known SAML metadata aggregator implementations used for interfederation purposes:
- Shibboleth Metadata Aggregator (Java, XSLT)
- Python Federation Feeder (pyFF)
AFAIK the latter is used by eduGAIN to aggregate the metadata for R&E federations worldwide. So far 37 R&E federations have joined eduGAIN, and of those, 28 are actively exporting metadata.
InCommon joined eduGAIN in April 2014 amid great fanfare (see the press release) but the truth of the matter is that InCommon has been slow to interfederate. I’m happy to say that has been turned around, largely due to the efforts of Ian Young, perhaps the world’s foremost expert on metadata, metadata aggregation, and interfederation. With Ian’s help, InCommon is quietly making its way onto the interfederation scene.
For instance, InCommon is poised to announce a Per-Entity Metadata Pilot Study, an activity previously recommended by the Metadata Distribution WG. To support this pilot study, we’ve deployed an instance of a Metadata Query Server based on Ian’s mdq-server reference implementation of the Metadata Query Protocol.
In parallel with the pilot study, InCommon Operations will deploy new tooling based on the Shibboleth Metadata Aggregator. This tooling will allow us to ramp up our export activities, at which point all InCommon participants will be given the opportunity to export their entity metadata to eduGAIN.
To be eligible to participate in interfederation activities, an organization must be an InCommon participant in good standing. Beyond that, IdP and SP metadata exported to eduGAIN must meet certain basic requirements expected of all SAML deployments. Next week’s TechEx conference will give us an opportunity to discuss these requirements with the InCommon community. Please join us at TechEx in Indianapolis!
Asserting ePPN Across the Gateway
It is generally recognized that asserting scoped attributes across a gateway is problematic. Social gateways are particularly troublesome since few social IdPs assert an attribute that maps naturally to eduPersonPrincipalName, which is a scoped attribute known to be required by many RPs in the R&E space.
Executive Summary
- The user’s email address is a poor choice for
eduPersonPrincipalNameasserted by a gateway. - The OpenID Connect subject identifier (sub) more accurately maps to
eduPersonTargetedIDoreduPersonUniqueId, noteduPersonPrincipalName. - For a social gateway, the recommended value of
eduPersonPrincipalNameiswhereuser+domain1@social_idp.domain2
user@domain1is the email address of the user,social_idpis the name of the social provider, anddomain2is a domain owned by the organization that owns and operates the gateway.
Introduction
It is well known that eduPersonPrincipalName (ePPN) is a globally unique, persistent identifier for the user. For level-setting purposes, we begin with the following facts about persistent identifiers and scoped attributes.
Persistent Identifiers
- Definition. A persistent identifier for the user is one that spans multiple SSO sessions.
- Although
ePPNis a persistent identifier, it is not intended to be permanent. Relying parties certainly prefer thatePPNremain stable but users can and do change theirePPNfor a variety of reasons. - Although non-reassignment is a highly desirable property of any persistent identifier,
ePPNdeployments are not guaranteed to be non-reassigned (but often are since it is understood that a persistent, non-reassigned identifier is more valuable than one that is not).
Scoped Attributes
ePPNis the primary example of a scoped attribute.ePPNis globally unique by virtue of its scope, which by convention is a DNS name.- The scope part of a scoped attribute indicates the asserting authority. This is why a scope is a DNS name by convention.
- A trusted third party (such as a federation) ensures that the scopes listed in metadata are rooted in registered domains owned by the organization deploying the IdP.
- Normally an IdP asserts a scoped attribute with a scope part for which the IdP is authoritative. Likewise an SP filters scoped attributes for which the IdP is not authoritative, at least by default.
Email Address as ePPN?
If you were an enterprise architect designing an identity management system from scratch, it would be in your best interest to define ePPN such that it was a routable email address. There are many reasons for this, not the least of which is the fact that SaaS services invariably use email address as a user ID.
That said, when mapping attributes across a social gateway, resist the urge to map the user’s email address to ePPN, even if the social IdP asserts email addresses known not to be re-assigned. Why? Because the right hand side of an email address asserted by a social IdP can be just about anything, which forces the RP to accept practically any scope from the corresponding gateway. That totally defeats the purpose of scoped attributes.
Consider Google, for example. Since a Google Apps subscriber provisions local email addresses in Google Apps (e.g., user@university.edu), the Google IdP will assert arbitrary email addresses (not just @gmail.com email addresses). Thus mapping email address to ePPN is quite possibly the worst thing you could do.
The OIDC Sub Claim as ePPN?
The OpenID Connect (OIDC) subject identifier (sub) is an opaque, non-reassigned identifier for the user, scoped to the issuer. Coupled with the OIDC issuer identifier (iss) the sub claim is a stable, globally unique identifier for the user. As such the sub claim closely aligns with the SAML2 Persistent NameID or the equivalent eduPersonTargetedID attribute. Unlike eduPersonTargetedID, however, the sub claim is not a targeted identifier.
The sub claim is also closely aligned with eduPersonUniqueId. The latter, however, is a scoped attribute, which leads to complications. The obvious choice of scope value is @google.com but this scope MUST NOT be asserted in gateway metadata. An RP would have to carefully configure the handling of scope @google.com in its SAML software. To make matters worse, eduPersonUniqueId is new and not widely deployed, so one should expect little support for it in existing SAML implementations.
Finally, mapping the sub claim to ePPN is least desirable for the following reasons:
- Both
eduPersonTargetedIDandeduPersonUniqueIdare better suited to carry thesubclaim. - Like
eduPersonUniqueId,ePPNis a scoped attribute, with all the same problems. - The RP does not expect the left hand side of
ePPNto be opaque.
All in all, the sub claim is perhaps best mapped to eduPersonTargetedID.
Best Practices for Gateway ePPNs
For a social gateway, the recommended value of ePPN is:
user+domain1@social_idp.domain2
where user@domain1 is the email address of the user, social_idp is the name of the social provider, and domain2 is a domain owned by the organization that owns and operates the gateway. For example, my ePPN asserted by the Internet2 Google Gateway is:
trscavo+gmail.com@google.incommon.org
Since Internet2 is a Google Apps for Education campus, I am also known as:
trscavo+internet2.edu@google.incommon.org
since Google will readily assert my Internet2 email address trscavo@internet2.edu if I happen to log in via the Internet2 IdP.
What happens when an RP that has been using a central gateway chooses to run its own local gateway? In that case, a migration will be necessary since the scope on the ePPN will no doubt change. Thus the best choice of scope in the first place is a stable value that won’t change over time, regardless of who owns and operates the gateway.
For example, consider the Internet2 Google Gateway again. The scope @google.incommon.org was chosen because:
- Internet2 owns the registered domain
incommon.org, which is a required characteristic of all scopes in metadata. - The subdomain
google.incommon.orgmakes it easy for Internet2 to support other social providers if and when the time comes. (For instance, a Facebook Gateway would have scope@facebook.incommon.org.) - If the Internet2 Google Gateway were promoted to a centrally-run gateway for other (non-Internet2) services, the scope would not have to change.
Now observe that the Internet2 service wiki.shibboleth.net does not use the Internet2 Google Gateway today…but it could. The best scope for this particular service would be @google.shibboleth.net since then the service could easily migrate to its own gateway in the future if desired. We could modify the existing gateway implementation to assert an ePPN with scope @google.shibboleth.net but we wouldn’t be able to assert that scope in metadata since Internet2 does not own the registered domain shibboleth.net. In that case, the SAML software protecting wiki.shibboleth.net would have to be locally reconfigured to accept scoped attributes of the form value@google.shibboleth.net from the Internet2 Google Gateway.
Research and Scholarship as a Catalyst for Interfederation
It’s been almost two and a half years since the InCommon Research & Scholarship (R&S) Category opened its doors. Today there are 23 R&S SPs, a small but important category of InCommon services. Perhaps more importantly, 90 InCommon IdPs have openly declared their support for R&S. Last month alone, 10 IdPs threw their hat into the ring, the most in any single month thus far. Could it be that R&S has finally reached critical mass?
These and other events make me optimistic that the answer to the previous question might be yes:
- The Research & Scholarship Entity Category was adopted by REFEDS [Feb 2014]
- InCommon officially joined the international eduGAIN consortium [Apr 2014]
Together these events place the Research & Scholarship Entity Category at the very center of the international stage.
REFEDS R&S
In February 2014, exactly two years after the first InCommon Service Provider was accepted into the R&S program, the REFEDS steering committee approved and published its own REFEDS Research & Scholarship Entity Category specification. Modeled closely after the InCommon R&S Category definition, the REFEDS version enables R&S interoperability across more than 30 federations worldwide. At least a handful of these federations are implementing REFEDS R&S as we speak. More are expected to follow in the months ahead.
Here in the US, the migration to REFEDS R&S has already begun. To ensure compatibility with other federations, InCommon will ask R&S service owners to re-apply for R&S while focusing on the differences between InCommon R&S and REFEDS R&S (which fortunately are few). Once all the R&S SPs have migrated to REFEDS R&S, the R&S IdPs will be asked to make a small, one-time change to their attribute release policy. At that point the migration to the international REFEDS R&S standard will be complete.
eduGAIN
The international eduGAIN service is the mechanism by which interfederation takes place. Federations worldwide export entity metadata to eduGAIN while those same federations turn around and import metadata from eduGAIN, adding the imported metadata to the aggregates distributed to their respective members.
InCommon officially joined eduGAIN in April 2014. We don’t yet export metadata to eduGAIN, but when we do, expect the R&S SPs to be among the first to go. Indeed, the InCommon R&S entities (both SPs and IdPs) are the best candidates for interfederation since they are already committed to usability, interoperability, security, and privacy.
The Critical Importance of R&S
Interfederation tends to magnify the strengths and weaknesses of the federated model, in the following sense. Suppose you’re an SP that wants to reach the widest possible audience, that is, the entire R&E community worldwide. Three things have to happen: 1) the SP has to consume all the IdP metadata in the world; 2) likewise all the IdPs in the world need to consume the SP’s metadata; and 3) all IdPs have to release the necessary attributes to the SP. Although (1) and (2) seem daunting, that is precisely the function of eduGAIN, and so there is hope.
No amount of metadata sharing will help realize (3), however. Attribute release is the number one problem in the InCommon Federation. It's why we invented R&S in the first place. At the interfederation level, attribute release is further complicated by international privacy laws. It is unlikely attributes will flow between countries without some agreements eventually being in place. This problem is being addressed on multiple fronts, including R&S. Although it’s barely more than an experiment at this point, the REFEDS Research & Scholarship Entity Category is the best chance we have of making interfederation a worthwhile exercise in the short term.
Phasing Out the Use of SHA-1
As of January 1, 2014, NIST disallows the use of the SHA-1 digest algorithm in conjunction with digital signatures (see: NIST SP 800-57 Part 1, Revision 3, July 2012, Tables 3 and 4). This was a major driver behind the Phase 1 Recommendations of the Metadata Distribution Working Group, which gave rise to the Phase 1 Implementation Plan, an effort that is nearing completion.
On December 18, 2013, InCommon began a migration process for phasing out the use of the SHA-1 digest algorithm within the Federation. The next milestone event in that migration process is scheduled to take place on June 30, 2014, as described in the next section.
Contents:
SHA-1 and SAML Metadata
All SAML metadata distributed by InCommon is digitally signed for authenticity and integrity. The XML signature on the metadata uses a hashing algorithm, first to bulk-digest the XML metadata and then to sign the XML document itself. Although these are independent operations, a single hashing algorithm is often used for both purposes, and until recently, the SHA-1 hashing algorithm was used exclusively.
At this point in time (May 2014), all but one of the metadata aggregates published by InCommon are signed using the SHA-256 digest algorithm. The fallback aggregate, which still uses the SHA-1 digest algorithm, will be upgraded by the middle of this calendar year.
On June 30, 2014, the fallback metadata aggregate will be synced with the production metadata aggregate. That is, after June 30, all metadata aggregates published by the InCommon Federation will be signed using the SHA-256 digest algorithm. To avoid complications, all SAML deployments are strongly encouraged to migrate to the production aggregate or the preview aggregate now but no later than June 30, 2014.
A frequently asked question is: What will happen if I do nothing? One answer is: In 90% of the cases, if you do nothing, your deployment will continue to function as normal after June 30th. We say this because we are confident that the majority of SAML deployments in the InCommon Federation are compatible with SHA-256.
Instead of drilling down on the remaining 10%, consider this: We know with 100% certainty that the fallback metadata aggregate will be signed using a SHA-256 digest algorithm beginning on June 30th, so knowing nothing else but that simple fact, we conclude that all deployers are better off explicitly migrating to the production aggregate than they are doing nothing because all other things being equal (which they are) a controlled migration is always safer than a forced migration.
Indeed, migrating to the production aggregate is as simple as changing the URL in your metadata configuration. Go ahead, schedule that simple configuration change subject to whatever change management policy you have in place at your site. You’ll know within minutes if it’s going to work, and honestly, there is a very high probability it will Just Work. If it does, you’re home free because you can do the rest of the migration on your own time. If it doesn’t work, you can quickly back out the change and invoke Plan B.
All SAML deployments in the InCommon Federation should migrate to the production metadata aggregate (or the preview metadata aggregate) now. Recommended configuration options for Shibboleth and simpleSAMLphp are documented in the wiki.
So why does the simple migration outlined above work without bootstrapping an authentic copy of the new metadata signing certificate? Because a conforming metadata consumption process ignores all the certificate details except the public key bound to the certificate, and the public key has not changed.
For more information, see: Metadata Migration Process
Questions? Join this mailing list: https://lists.incommon.org/sympa/info/metadata-support
SHA-1 and X.509 Certificates
SAML entities (IdPs and SPs) manage at least two types of private keys: TLS keys and SAML keys. The corresponding public keys are bound to X.509 certificates, which are signed of course. Like the signature on XML metadata, the signature over an X.509 certificate relies on a digest algorithm, typically the SHA-1 digest algorithm.
SHA-1 and TLS Certificates
As you probably know, SAML endpoints in metadata are protected with TLS. In particular, browser-facing endpoints in metadata are associated with TLS certificates signed by a trusted CA (i.e., a CA trusted by your browser). Browser-facing TLS certificates do not appear in metadata and are therefore out of scope with respect to the Implementation Plan.
Endpoints in metadata that support the so-called back-channel protocols are associated with SAML certificates in metadata. These and other certificates in metadata are discussed in the next section.
Not surprisingly, the signature over a trusted (browser-facing) TLS certificate typically relies on the SHA-1 digest algorithm, and so the CA and browser vendors are also migrating to the SHA-2 family of digest algorithms. This will be the topic of a future blog post.
SHA-1 and SAML Certificates
The rest of this section concentrates on the public keys bound to certificates in SAML metadata.
A SAML entity is a secure web server that produces and/or consumes SAML messages. These SAML messages may be signed or encrypted using asymmetric crypto operations. A relying party uses a trusted public key in metadata to verify an XML signature or perform an XML encryption operation. These public keys are bound to long-lived, self-signed certificates in metadata. Like all X.509 certificates, the signature on a certificate in metadata uses a hashing algorithm, which is almost always the SHA-1 hashing algorithm.
Fortunately, there are absolutely no security considerations concerning the signature on certificates in metadata. In fact, the only concern is the actual public key bound to the certificate in metadata. Every other aspect of the certificate is ignored by the SAML software (or at least software that’s doing the Right Thing). That’s why InCommon recommends the use of long-lived, self-signed certificates in metadata: the focus is on the key, not the certificate.
Don't fiddle with the signature on self-signed certificates in metadata. Until the signature on a certificate in metadata actually becomes an interoperability issue, it is best to leave it alone.
SHA-1 and SAML Assertions
Like metadata, SAML messages may be digitally signed for authenticity and integrity. Any SAML entity (IdP or SP) may sign a message but in practice it is the IdP that wields a signing key since SAML assertions issued by the IdP MUST be signed. The SP uses the IdP’s public signing key in metadata to verify the signature on the assertion just-in-time, that is, when the assertion is presented to the SP by the browser user.
It is believed that most IdPs in the InCommon Federation are signing assertions using the SHA-1 digest algorithm. This is because most IdP deployments use the Shibboleth IdP software, which is known to support SHA-1 only, at least out of the box.
SAML deployers should take note of the following facts:
- If your SAML deployment can consume metadata signed using the SHA-256 digest algorithm, it very likely can consume SAML assertions signed using the SHA-256 digest algorithm.
- The ability to sign SAML assertions using the SHA-256 digest algorithm is not fully supported by the Shibboleth IdP software (but please read on).
Clearly the former is an enabler while the latter is an inhibitor. Without ample software support, InCommon can not realistically recommend a firm SHA-256 migration path for IdPs. The best we can do is to ensure ubiquitous SHA-256 support at the SP and then encourage individual IdPs to devise a migration plan that makes sense for them.
After June 30, 2014, almost all SPs in the InCommon Federation will support SHA-256. Given this, each IdP should decide, subject to its own unique set of circumstances, when to begin signing SAML assertions using the SHA-256 digest algorithm.
SimpleSAMLphp has good support for signing assertions using the SHA-256 digest algorithm. It can be configured to sign assertions on a per-SP basis, that is, a simpleSAMLphp IdP can sign assertions using the SHA-1 digest algorithm for some SPs and the SHA-256 digest algorithm for others. Therefore sites running the simpleSAMLphp IdP software can and should migrate to SHA-256 as soon as possible. A perfectly reasonable strategy would be to configure the use of SHA-256 by default but to fall back to SHA-1 for those few remaining SPs (perhaps external to InCommon) unable to handle SHA-256.
To enable SHA-2 support in the Shibboleth IdP, you can use a 3rd-party extension to enable SHA-2 capability for Shibboleth IdP versions 2.3 and later. Note that the Shibboleth configuration is all or none, either SHA-1 or SHA-256, so Shibboleth IdPs are advised to wait until after June 30, 2014, when all SPs will be consuming metadata signed using a SHA-256 digest algorithm.
Actually, it’s a bit more complicated than that for Shibboleth deployers. Shibboleth IdP v3 is due out later this calendar year and of course v3 will fully support the SHA-2 family of digest algorithms, including SHA-256. So the question for each Shibboleth deployer is whether to install the extension in their current deployment of Shibboleth IdP v2 or wait for Shibboleth IdP v3?
For those IdPs certified or looking to be certified in the Assurance Program, the Bronze and Silver Profiles require that "Cryptographic operations shall use Approved Algorithms" and since SHA-1 is no longer an "Approved Algorithm," it can not be used to meet the requirements of Bronze or Silver. However, the InCommon Assurance Program is working on releasing a variance to the requirements (called an Alternative Means) to permit the use of SHA-1 until January 15, 2015.
Be advised that if you intend to interoperate with a federal agency SP that requires Bronze or Silver, assertions MUST be signed using a SHA-2 digest algorithm. Such an IdP should begin the migration to SHA-256 immediately.
InCommon Operations will remove the legacy metadata download endpoint (currently, a redirect) on Wednesday, February 14, 2018
All metadata clients that download metadata from this endpoint should switch to one of the production endpoints noted in: Metadata Aggregates before that date. Failure to do so will cause your SAML deployment to break. This page is being preserved for legacy/archival purposes. Please disregard the content below.
Phasing Out the Legacy Metadata Aggregate
On March 29, 2014, the legacy metadata aggregate at location
will be replaced with a redirect to the following new location:
All deployers are advised to migrate to one of the new metadata aggregates ASAP but no later than March 29, 2014.
In recent weeks, a number of people have asked me: What will happen if I do nothing? One answer is:
In more than 90% of the cases, if you do nothing, your deployment will continue to function as normal after March 29th.
We could drill down on that other 10% but consider this: We know with 100% certainty that a redirect will be installed on March 29th, so knowing nothing else but that simple fact, we can conclude that all deployers are better off migrating to the new fallback aggregate than they are doing nothing because all other things being equal (which they are) a controlled migration is always safer than a forced migration.
If you’re running Shibboleth, migrating to the new fallback aggregate is as simple as changing the URL in your Shibboleth Metadata Config. Go ahead, schedule that simple configuration change subject to whatever change management policy you have in place. You’ll know in a few moments if it’s going to work, and honestly, there is a very high probability it will just work. If it does, you’re home free because you can complete the rest of the migration on your own time. If it doesn’t work, you can quickly back out the change and invoke Plan B.
So why does that simple config change work without bootstrapping an authentic copy of the new metadata signing certificate? Because Shibboleth ignores all the certificate details except the public key bound to the certificate, and that key hasn’t changed, so we're good to go.
For more detailed information, consult the Metadata Migration Process wiki page.
Questions? Join this mailing list: https://lists.incommon.org/sympa/info/metadata-support
The Rise of OpenID Connect
The OpenID Connect standard was ratified by the membership of the OpenID Foundation on February 26, 2014. The developers of the OpenID Connect standard have been hinting at this event for months but the announcement was accompanied by much fanfare, accolades, and dancing in the streets. (Well, maybe not the dancing part.) Kudos to the architects of OpenID Connect!
Technically, OpenID Connect is a profile of OAuth2, but practically speaking, OpenID Connect builds on the success of SAML2 Web Browser SSO. In addition, OpenID Connect adds support for session management and single logout, a new discovery mechanism, and the elusive non-browser use case. These are major new features that have captured the attention of the identity community. Moreover, the basic file and message format of OpenID Connect is JSON (not XML), which will no doubt be a welcome change by many deployers and developers.
OpenID Connect is already in wide use on the open Internet. Google, Salesforce, and other forward thinking companies have supported early versions of OpenID Connect for some time. These and other vendors will be the first to support the new standard (if they don’t already do so). Recently, Yahoo announced its intent to migrate to OpenID Connect as well. AFAIK, Microsoft does not yet support it but the primary editor of the OpenID Connect specification is a Microsoft employee, so I’ll be surprised if Microsoft doesn’t throw its hat into the ring Real Soon Now.
So there you have it. All the major email providers either do (or will) support OpenID Connect. This alone begs our attention. What does this mean for the InCommon Federation and other R&E Federations worldwide, all of which are based on SAML? Is SAML really dead?
Maybe that’s the wrong question. Instead let’s consider how SAML-based Federations will eventually leverage the new OpenID Connect protocol. In the short term, one possible strategy is to translate OpenID Connect assertions into SAML assertions so that SAML-based relying parties can leverage the identity attributes asserted via OpenID Connect. Since the early adopters of OpenID Connect are vendors on the open Internet, we’re talking about so-called social identity (although new terminology is probably needed at this point).

Here’s an example. Since October 2013, Internet2/InCommon has been running a Google Gateway in production (click the image on the right). Up until now, that Gateway has leveraged the Google OpenID 2.0 IdP. (OpenID 2.0 is a legacy federation protocol, with almost no resemblance to OpenID Connect.) Since Google has deprecated its support for OpenID 2.0, we are migrating the Internet2/InCommon Google Gateway to OpenID Connect. This migration will be complete by March 15, 2014.
The Google Gateway functions as an IdP of Last Resort for Internet2/InCommon services. A user whose home organization does not deploy an IdP or does not release the required attributes, can use the Google Gateway to log into our services. Since many users already have Google IDs, this can be done without having to create yet another username and password. This is a big win for everybody, especially the end user.

As a privacy-preserving feature, Google requires explicit user consent for each and every transaction (click the image on the left). To further protect privacy, only three attributes are allowed to transit the Gateway: email, first name, and last name. If Google asserts additional attributes, they are simply dropped on the Gateway floor. Finally, since Google transacts with the Gateway only, the browsing habits of users are hidden from Google, which further enhances privacy.
Where is all this going? Honestly, I don’t know, but instead of sitting around and scratching our heads, we’ve started to leverage social identity and experiment with OpenID Connect. This addresses two of three major limitations of the federated identity approach (i.e., coverage and attribute release), and at the same time permits us to hedge our bets on the future of SAML as a federation protocol.
Survival in a World of Zero Trust
Try the following Thought Experiment. Take 100 random users, put them in a room, and ask them to log into your favorite federated web app. If you tell them to first go create an account with some IdP of Last Resort, they will probably groan and quite likely not grok the value of what you are trying to demonstrate. Indeed.
Instead tell them to choose their favorite social IdP on the discovery interface. This will immediately win over a sizable proportion of your audience who will blithely log into your app with almost zero effort (since most social IdPs will happily maintain a user session indefinitely).
However, as Jim Fox demonstrated on the social identity mailing list the other day, not all users feel comfortable performing a federated login at a social IdP. Some users have a healthy distrust for social IdPs, and moreover, that lack of trust is on the rise. So be it.
What can we conclude from this Thought Experiment? Here's my take. Bottom line: Federation is Hard. By no means is the Federated Model a done deal. It may or may not survive, and moreover, I can't predict with any accuracy what will prevail.
That said, I believe in the Federated Model and I want it to work in the long run, so here's what I think we should do in the short term. The appearance of social IdPs on the discovery interfaces of Federation-wide SPs is an inevitability. The sooner we do it, the better off we as users will be. For some (many?), this will simplify the federation experience, and we dearly need all the simplification we can get.
We don't need any more IdPs of Last Resort in the wild, at least not until the trust issues associated with IdPs have been worked out. I'm talking of course about multifactor authentication, assurance, user consent, and privacy, all very hard problems that continue to impede the advance of the Federated Model. In today's atmosphere of Zero Trust, it makes absolutely no sense to keep building and relying on password-based SAML IdPs. That elusive One IdP That Rules Them All simply doesn't exist. We need something better. Something that's simple, safe, and private.
If you're still reading this, you'll want to know what the viable alternatives are. Honestly, I don't know. All I can say is that I'm intrigued by the user centric approaches of the IRMA project and the FIDO Alliance. If similar technologies were to proliferate, it would be a death knell for the centralized IdP model. In its place would rise the Attribute Authority, and I don't mean the SSO-based AAs of today. I mean standalone AAs that dish out attribute assertions that end users control. This is the only approach I can see working in a World of Zero Trust.
Certificate Migration in Metadata
In the last few months, InCommon Operations has encountered two significant interoperability “incidents” (but it is likely there were others we didn’t hear about) that were subsequently traced to improper migration of certificates in metadata. When migrating certificates in metadata, site administrators are advised to carefully follow the detailed processes documented in the wiki. These processes have been shown to maintain interoperability in the face of certificate migration, which tends to be error prone.
Of particular importance is the migration of certificates in SP metadata since a mistake here can affect users across a broad range of IdPs (whereas a mistake in the migration of a certificate in IdP metadata affects only that IdP’s users). When migrating a certificate in SP metadata, the most common mistake is to add a new certificate to metadata before the SP software has been properly configured. This causes IdPs to unknowingly encrypt assertions with public keys that have no corresponding decryption keys configured at the SP. A major outage at the SP will occur as a result.
Another issue we’re starting to see is due to increased usage of Microsoft AD FS at the IdP. As it turns out, AD FS will not consume an entity descriptor in SP metadata that contains two encryption keys. To avoid this situation, the old certificate being migrated out of SP metadata should be marked as a signing certificate only, which avoids any issues with AD FS IdPs. See the Certificate Migration wiki page for details.
Please share this information with your delegated administrators. By the way, if you’re not using delegated administration to manage SP metadata, please consider doing so since this puts certificate migration in the hands of individuals closest to the SP.
Social Identity: A Path Forward
Social Identity was a hot topic at Identity Week in San Francisco last November. Some of the participants questioned the wisdom of Social Identity in the first place: Do we really want to give the keys to the kingdom to Google? Wouldn’t it be in the Federation's best interest to continue to encourage campuses to deploy their own IdPs?
I think we can have our cake and eat it too if we properly limit the scope of a centralized Social Gateway for all InCommon participants.
First, what problem are we trying to solve? The primary motivation for a centralized Social Gateway is to attract Federation-wide SPs to join InCommon. Jim Basney says it best: Given the current penetration of InCommon within US higher education (approximately 20% of US HE institutions operate InCommon IdPs), a “catch-all” IdP is essential to provide a complete federation solution. A Social Gateway would go a long way towards filling this gap.
Second, what problems are we trying to avoid? Most importantly, we want campuses to continue their orderly transition to a federated environment, and so a centralized gateway should not be seen as an alternative to deploying a local IdP.
Not surprisingly, there is also a privacy concern. Like most other Social IdPs in this post-Snowden era, Google is seen by many as a privacy risk. To minimize this risk, we can (and should) limit the attributes that transit the gateway regardless of the attributes Google actually asserts. Moreover, note that a social gateway is inherently privacy-preserving in the sense that it masks (from Google) the end SPs the user visits.
With that background, consider the following proposed centralized Google Gateway for all InCommon participants:
- lightweight deployment
- reassert email and person name and that’s all; any other attributes asserted by Google are routinely dropped on the Gateway floor
- manufacture and assert ePPN at the Gateway
- no extra attributes, no trust elevation, no invitation service
Such a gateway can not be used in lieu of a campus IdP. If a campus wants to go that route, presumably it can deploy a campus-based gateway on its own.
It is well known that a service provider can request attributes by reference using the SAML AuthnRequest Protocol. Usually the reference is to an <md:AttributeConsumingService> element in metadata, but as discussed in a recent blog post on data minimization, metadata is not required. The identity provider may map the reference to an attribute bundle in whatever way makes sense.
Below we describe a non-use case for the <md:AttributeConsumingService> element in the InCommon Federation. In this case, the service provider doesn't request attributes at all. Instead, the identity provider releases a predefined bundle of attributes to all service providers in a class of service providers called an Entity Category.
There is a class of service providers called the Research and Scholarship Category of service providers (SPs). Associated with the Research and Scholarship (R&S) Category is an attribute bundle B. An identity provider (IdP) supports the R&S Category if it automatically releases attribute bundle B to every SP in the R&S Category.
Every SP in the R&S Category is required to have an <md:AttributeConsumingService> element in its metadata. Now suppose an SP encodes attribute bundle A in metadata such that A is a subset of B. In other words, the SP requests fewer attributes than what the IdP has agreed to release. In this case, an IdP can choose to release A and still support the R&S Category.
Although the software supports this behavior, few (if any) IdPs are configured this way. Instead, IdPs release B to all SPs regardless of the attributes called out in SP metadata. Why? Well, it's easier for the IdP to release B across the board but there's another more important reason that depends on the nature of attribute bundle, so let me list the attributes in the bundle along with some sample values:
eduPersonPrincipalName:trscavo@internet2.edu
mail:trscavo@internet2.edu
displayName:Tom Scavo OR (givenName:Tom AND sn:Scavo)
Note that all of the attributes in this bundle are name-based attributes. If you're going to release one, you may as well release all of them since each attribute valu encodes essentially the same information. This is why IdPs choose to release the entire bundle across the board: there are no privacy benefits in releasing a strict subset, and so it's simply easier to release all attributes to all R&S SPs.
I'm sure one could come up with a hypothetical use case for which there are real privacy benefits in releasing subset A of bundle B but we haven't bumped into such a use case yet. In any event, note the following:
- AFAIK, no software implementation supports more than one
<md:AttributeConsumingService>element in metadata so there isn't much point in calling out the index of such an element in the<samlp:AuthnRequest>.
- Use of the
AttributeConsumingServiceIndexXML attribute as described in the blog post is interesting, but entity attributes give the same effect, and moreover, entity attributes are in widespread use today (at least in higher ed).
- I doubt any IdP in the InCommon Federation would be inclined to implement a liberal attribute release policy such as "release whatever attributes are called out in the
<md:AttributeConsumingService>element in metadata" since this is a potentially serious privacy leak.
This leads to the following prediction: the <md:AttributeConsumingService> element in metadata and the AttributeConsumingServiceIndex XML attribute in the <samlp:AuthnRequest> will turn out to be historical curiosities in the SAML protocol. At this point, the best approach to attribute release appears to be the Entity Category (of which the R&S Category is an example).
ForceAuthn or Not, That is the Question
Depending on your point of view, SAML is either a very complicated security protocol or a remarkably expressive security language. Therein lies a problem. A precise interpretation of even a single XML attribute is often elusive. Even the experts will disagree (at length) about the finer points of the SAML protocol. I’ve watched this play out many times before.
In this particular case, I’m referring to the ForceAuthn XML attribute, a simple boolean attribute on the <samlp:AuthnRequest> element. On the surface, its interpretation is quite simple: If ForceAuthn="true", the spec mandates that “the identity provider MUST authenticate the presenter directly rather than rely on a previous security context.” (See section 3.4.1 of the SAML2 Core spec.) Seems simple enough, but a google search will quickly show there are wildly differing opinions on the matter. (See this recent discussion thread re ForceAuthn on the Shibboleth Users mailing list, for example.) I’ve even heard through the grapevine that some enterprise IdPs simply won’t do it. By policy, they always return a SAML error instead (which is the IdP’s prerogative, I suppose).
For enterprise SPs, such a policy is one thing, but if that policy extends outside the enterprise firewall...well, that’s really too bad since it reduces the functionality of the SAML protocol unnecessarily. OTOH, an SP that always sets ForceAuthn="true" is certainly missing the point, right? There must be some middle ground.
Here’s a use case for ForceAuthn. Suppose the SP tracks the user's location via IP address. When an anonymous user hits the SP, before the SP redirects the browser to the IdP, the IP address of the browser client is recorded in persistent storage and a secure cookie is updated on the browser. Using the IP address, the SP can approximate the geolocation of the user (via some REST-based API perhaps). Comparing the user's current location to their previous location, the SP can make an informed decision whether or not the user should be explicitly challenged for their password. If so, the SP sends a <samlp:AuthnRequest> to the IdP with ForceAuthn="true".
Behaviorally, this leads to a user experience like the one I had recently when I traveled from Ann Arbor to San Francisco for Identity Week. When I arrived in San Francisco, Google prompted me for my password, something it rarely does (since I’m an infrequent traveler). Apparently, this risk-based authentication factor protects against someone stealing my laptop, defeating my screen saver, and accessing my gmail. This is clearly a Good Thing. Thank you, Google!
This use case avoids the ForceAuthn problem described above, that is, the SP now has some defensible basis for setting ForceAuthn="true" and the debate between SPs and IdPs goes away. Simultaneously, we raise the level of assurance associated with the SAML exchange and optimize the user experience. It's a win-win situation.
The downside of course is that this risk-based authentication factor is costly to implement and deploy, especially at scale. Moreover, if each SP in the Federation tracks geolocation on its own, the user experience is decidedly less than optimal. But wait…distributed computing to the rescue! Instead of deploying the risk-based factor directly at the SP, we can deploy a centralized service that passively performs the geolocation check described above. There are multiple ways to deploy such a centralized service: 1) deploy the service as an ordinary SAML IdP; 2) deploy the service in conjunction with IdP discovery; or 3) invent a completely new protocol for this purpose. There are probably other ways to do this as well.
Hey, SP owners out there! If such a service existed, would you use it?
On December 18th, InCommon Operations will deploy three new metadata aggregates on a new vhost (md.incommon.org). All SAML deployments will be asked to migrate to one of the new metadata aggregates as soon as possible but no later than March 29, 2014. In the future, all new metadata services will be deployed on md.incommon.org. Legacy vhost wayf.incommonfederation.org will be phased out.
An important driver for switching to a new metadata server is the desire to migrate to SHA-2 throughout the InCommon Federation. The end goal is for all metadata processes to be able to verify an XML signature that uses a SHA-2 digest algorithm by June 30, 2014. For details about any aspect of this effort, see the Phase 1 Implementation Plan of the Metadata Distribution Working Group.
Each SAML deployment in the Federation will choose exactly one of the new metadata aggregates. If your metadata process is not SHA-2 compatible, you will migrate to the fallback metadata aggregate. Otherwise you will migrate to the production metadata aggregate or the preview metadata aggregate, depending on your deployment. You can find more information about metadata aggregates on the wiki.
Questions? Subscribe to our new mailing list and/or check out our FAQ:
Help: help@incommon.org
FAQ: https://spaces.at.internet2.edu/x/yoCkAg
To subscribe to the mailing list, send email to sympa@incommon.org with this in the subject: subscribe metadata-support
An Overview of the Duo Security Multifactor Authentication Solution
Duo Security supports three classes of authentication methods:
- Duo Push
- Standard OATH Time-based One-Time Passcodes (TOTP)
- Telephony-based methods:
- OTP via SMS
- OTP via voice recording
- Voice authentication
The three classes of methods have different usability, security, privacy, and deployability characteristics.
Usability
Duo Push is highly usable. When people think of Duo, they usually think of Duo Push since there are numerous video demos of Duo Push in action. (Most authentication demos are boring, as you know, but Duo Push is an exception.)
Duo voice authentication is also highly usable. It is certainly less flashy (and it has other disadvantages as well) but its usability is more or less the same as Duo Push.
Standard OATH TOTP built into the Duo Mobile native mobile app is less usable. Transcribing a six-digit passcode will get old quickly if the user is asked to do it too often.
The telephony-based OTP methods are least usable. They are best used as backup methods or in conjunction with some other exceptional event.
Security
Duo Push and OATH TOTP are implemented in the Duo Mobile native app. As such, Duo Mobile is a soft token (in contrast to hard tokens such YubiKey). In general, soft tokens are less secure than hard tokens. (The Duo Mobile native app is not open source and so it’s unknown whether a 3rd-party security audit has been conducted on the software base.)
Duo Push uses asymmetric crypto. The private key is held by the Duo Mobile app. The app also manages a symmetric key used for OATH TOTP. A copy of the symmetric key is also held by the Duo cloud service. As the RSA breach showed, the symmetric keystore on the server is a weakness of OATH TOTP. Indeed, this is one reason why Duo Push was invented.
The above facts give Duo Push a security edge over OATH TOTP. Since both of them are implemented in Duo Mobile, and since the security of the Duo Mobile soft token depends intimately on the underlying operating system (iOS or Android, mainly), the two authentication methods are considered to be more or less equivalent.
The telephony-based methods are less secure, however. Telephony introduces yet another untrusted 3rd party. In fact, teleco infrastructure is considered by many to be hostile infrastructure that is best avoided except perhaps in exceptional situations such as backup scenarios.
Privacy
We consider the following aspects of the privacy question:
- The privacy associated with the user’s phone number
- The privacy characteristics of the Duo Mobile app
- The privacy characteristics of the mobile credential
It should be immediately obvious that the use of any telephony-based method requires the user to surrender one or more phone numbers to Duo. Whether or not that is acceptable depends on the environment of use.
It is worth noting that Duo Mobile itself does not require a mobile phone number. Indeed, Duo Mobile runs on any compatible mobile device, not just smartphones. For example, Duo Mobile runs on iPhones, iPads, and iPod Touch under iOS. Telephony is not strictly required.
It is not known exactly what phone data is collected by the Duo Mobile app. Although the Duo privacy statement appears reasonable to this author, YMMV.
To use the Duo cloud service, one or more mobile credentials are required. For the telephony-based methods, there is a binding between the user’s phone number and the Duo service, as already discussed.
To use Duo Mobile with the Duo service, a binding between some user identifier and the Duo service is required. Any simple string-based identifier will satisfy this requirement. The identifier may be opaque but that would render the Duo Admin web interface significantly less useful. Unless you intend to use the Duo Admin API, a friendly identifier such as email address or eduPersonPrincipalName is recommended, but even this can be avoided, as noted below.
If you prefer, you can persist the opaque Duo identifier created at the time of enrollment. This precludes the need to pass a local identifier to the Duo service; just pass the Duo identifier instead.
Deployability
Generally speaking, Duo has flexible deployment options. How you deploy Duo depends on your particular usability, security, and privacy requirements (see above).
Authentication
Duo technology is designed to be deployed at the service. For example, Duo supports VPNs (multiple vendors), off-the-shelf web apps (WordPress, Drupal, Confluence, etc.), custom web apps (via an SDK), Unix, and ssh.
Here are some integration tips:
- To integrate with a custom web app, use the Duo Web SDK to obtain a mix of authentication options including Duo Push, voice authentication, and one-time passcodes via Duo Mobile. The Duo Web interface also accepts one-time passcodes previously obtained by some out-of-band method, and in fact, the web interface itself allows the user to obtain a set of emergency passcodes on demand.
- If telephony-based methods are not an option, for either security or privacy reasons, integrate Duo into your web app using the low-level Duo Auth API.
- If you want to add a second factor to a non-web app, say, an email-based password reset function, consider using the Duo Verify API.
Out of the box, Duo integrates with enterprise SSO systems based on Shibboleth or Microsoft AD FS. Integration with other SSO systems is possible using the SDK or any of the APIs. For example, the Duo Shibboleth Login Handler uses the Web SDK.
Enrollment
Like authentication, how you enroll your users depends on your requirements:
- Since the Duo Web SDK incorporates telephony-based methods, the enrollment process must bind the user’s phone number with the Duo service. This is usually done by sending a link to the user’s mobile device vis SMS.
- To avoid telephony-based methods, the user scans a Qr code with the Duo Mobile app after authenticating with a username and password. While this has advantages, it requires the use of the low-level Auth API and is limited to mobile devices that support the native app (iOS, Android, etc.).
It is assumed that most of your users will enroll automatically via one of the methods mentioned above, but manual enrollment is possible. The Duo Admin web interface is provided for this purpose. The Duo Admin API is also provided so that admin functions can be accessed outside of the web interface.
Overheard yesterday:
If I can't use Duo Push, then I may as well use Google Authenticator.
Duo Mobile is a native mobile app. Duo Push is a capability of Duo Mobile on certain devices (iOS, Android, etc.). Duo Mobile protects two secrets: a symmetric key and a 2048-bit public/private key pair. The latter is used to secure the active, online, Duo Push authentication protocol.
In addition to Duo Push, the Duo Mobile app supports standard OATH TOTP, which requires a symmetric key. One copy of the symmetric key is protected by the Duo Mobile app while another copy is protected by the Duo cloud service. The two work together to provide a standard, offline, one-time password authentication protocol.
Google Authenticator supports OATH TOTP as well but the similarity with Duo Mobile ends there. Google offers no service analogous to the Duo cloud service, nor is there a server-side app you can run on-premise (but check out an open-source OATH TOTP server developed by Chris Hyzer at Penn). Google Authenticator does come with a PAM module but it is not enterprise grade by any means.
Bottom line: If you want to install an app on your mobile device that supports OATH TOTP, choose Duo Mobile. It's free, it works with all OATH TOTP-compatible servers (Google, Dropbox, AWS, etc.), it is well supported, and it does so much more (such as Duo Push, if and when you need it).
Multifactor Authentication in the Extended Enterprise
There are known pockets of multifactor in use in higher ed today but more often than not multifactor is deployed at the service itself. This is entirely natural since the SP has a vested interest in its own security. This tendency is often reflected in the technology solutions themselves, which are primarily enterprise authentication technology solutions at best.
Given a particular authentication technology, the decision whether or not to deploy is a complicated one. Two specific questions tend to select the most flexible solutions:
- Does the authentication technology solution integrate with the enterprise SSO system?
- Can the authentication technology solution be delivered “as-a-service?”
Let’s assume the answer to the first question is yes (an assumption on which the rest of this article is based). If the answer to the second question is no, we can conclude that the technology is limited to the enterprise, which means that one or the other of the SSO system or the authentication technology solution is limited to the enterprise. Regardless of the answers, this pair of questions tends to clarify the scope of the deployment so that there are no surprises down the road.
Enterprise Multifactor Authentication
In a federated scenario, the typical approach to multifactor authentication is to enable one or more additional factors in an existing enterprise IdP deployment that already authenticates its users with a username and password. This, too, is a natural thing to do, and it does have some advantages (to be discussed later) but this approach has at least one major drawback and, that is, it assumes all your users are managed by a single IdP. That’s a showstopper for any use case that touches the extended enterprise.
Patrick Harding refers to the notion of the extended enterprise in a recent article entitled Vanishing IT Security Boundaries Reappearing Disguised As Identity. Although the article itself focuses on identity technology, it’s the title that’s relevant here, which suggests that the limitations of the traditional security perimeter, typified by the firewall, give rise to the twin notions of identity and the extended enterprise. Neither is hardly a new concept but the notion highlights the limitations of what might be called the enterprise deployment model of multifactor authentication.
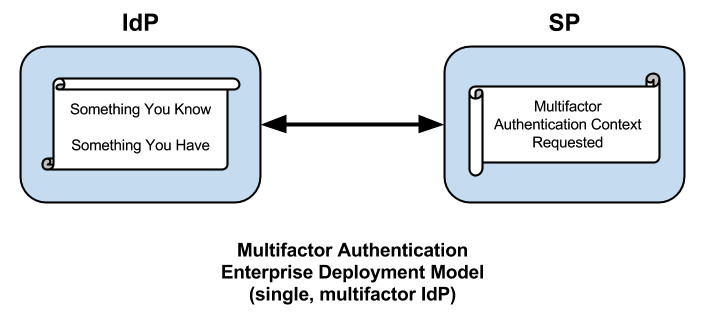
Integrating multifactor into the enterprise IdP is a definite improvement but it's still not good enough. How many times do you authenticate against your IdP in a typical work day? That's how many times you'll perform multifactor authentication, so your multifactor solution had better have darn good usability.
The fact is, unless your multifactor solution is passive, it will be less usable. The tendency will be to use the IdP's browser session to short-circuit an authentication request for multifactor. This is easier said, than done, however. Session management at the IdP was built with single factor authentication in mind. It'll be some time before SSO regains its footing at the IdP.
In the sections that follow, we show how to extend the enterprise deployment model in a couple of interesting and useful directions.
Distributed Multifactor Authentication
The core SAML spec alludes to a role called an IdP Proxy, apparently referring to a kind of two-faced IdP embedded in a chain of IdPs, each passing an assertion back to the end SP, perhaps consuming and re-issuing assertion content along the way. Since the SAML spec first appeared in 2005, the IdP Proxy has proven itself in production hub-and-spoke federations worldwide (particularly in the EU), but the idea of an IdP Proxy coupled with a multifactor authentication solution has only recently appeared. In particular, SURFnet began a project to deploy a Multifactor IdP Proxy in the SURFconext federation late in 2012. The Multifactor IdP Proxy enables what we call distributed multifactor authentication.
Consider the following use case. Suppose a high-value SP will only accept assertions from IdPs willing and able to assert a multifactor authentication context. Users, and therefore IdPs, are scattered all across the extended enterprise. Even if all the IdPs belong to the same federation, the trust problem becomes intractable beyond a mere handful of IdPs. A Multifactor IdP Proxy may be used to ease the transition to multifactor authentication across the relevant set of IdPs.
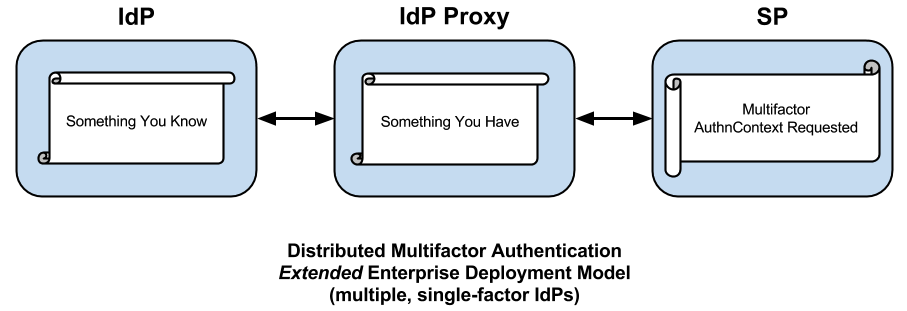
The Multifactor IdP Proxy performs two basic tasks: 1) it authenticates all browser users via some “what you have” second factor, and 2) it asserts a multifactor authentication context (plus whatever attributes are received from the end IdP). The Multifactor IdP Proxy we have in mind is extremely lightweight—it asserts no user attributes of its own and is therefore 100% stateless.
More importantly, the Multifactor IdP Proxy precludes the need for each IdP to support an MFA context. Instead each IdP can continue doing what it has been doing (assuming the existence of a sufficiently strong password in the first place). For its part, the SP need only trust one IdP partner to perform MFA, that is, the Multifactor IdP Proxy. If necessary, the SP can deploy the Multifactor IdP Proxy itself. In either case, the SP meets its high level of assurance requirements in relatively short order.
Step-Up Authentication
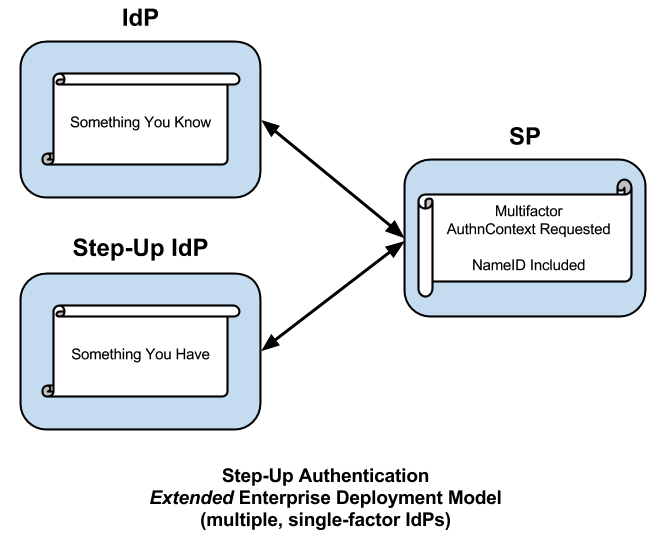
Consider the following general use case. A federated SP not knowing its users in advance accepts identity assertions from some set of IdPs. The SP trusts the assertion upon first use but—the network being the hostile place that it is—the SP wants assurances that the next time it sees an assertion of this identity, the user is in fact the same user that visited the site previously. The SP could work with its IdP partners to build such a trusted federated environment (or a federation could facilitate that trust on the SP’s behalf), but frankly that’s a lot of work, and moreover, all of the IdPs must authenticate their users with multiple factors before such a trusted environment may be realized. Consequently the SP takes the following action on its own behalf.
Instead of leveraging an IdP Proxy, or perhaps in addition to one, the SP leverages a distributed IdP for the purposes of step-up authentication. When a user arrives at the site with an identity assertion in hand, the SP at its discretion requires the user to authenticate again. This might happen immediately, as the user enters the front door of the site, or it might happen later, when the user performs an action that requires a higher level of assurance. The timing doesn’t matter. What matters is that the SP adds one or more additional factors to the user’s original authentication context, thereby elevating the trust surrounding the immediate transaction.
Comparative Analysis
Each of the methods described above has at least one disadvantage:
- Enterprise MFA is relatively difficult to implement. In general, the login handlers associated with multifactor IdPs must implement complex logic. SSO will suffer unless session management at the IdP is up to the task.
- Login interfaces for multifactor IdPs tend to be more complicated (but done right, this can turn into an advantage).
- Some user attributes cross the IdP Proxy more easily than others. In particular, scoped attributes present significant issues when asserted across the IdP Proxy.
- The IdP Proxy represents a single point of failure and a single point of compromise. Compensating actions at the IdP Proxy may be required.
- Since the SP must assert user identity to the step-up IdP, a non-standard authentication request may be required. Moreover, depending on the authentication technology solution in use, the SP may have to sign the authentication request.
On the other hand, the extended enterprise deployment models have some distinct advantages:
- Since distributed MFA and step-up authentication incorporate single-factor IdPs, these solutions (compared to enterprise MFA IdPs) are significantly easier to implement and deploy.
- For both distributed MFA and step-up authentication, the trust requirements of IdPs throughout the extended enterprise are minimized. Indeed, an IdP can continue to do what it already does since higher levels of assurance at the IdP are not required (but can be utilized if present).
- If necessary, the SP can assume at least partial ownership of its own trust requirements. The deployment strength of the step-up IdP can be completely determined by the SP. No external multifactor dependencies need to exist.
- By separating the factors across multiple IdPs, flexible distributed computing options are possible. In particular, Multifactor Authentication as-a-Service (MFAaaS) becomes an option.
The latter pair of advantages may be significant for some use cases. Unlike the enterprise deployment model (which relies on a single IdP), the extended enterprise surrounding the SP may leverage multiple IdPs. Moreover, those IdPs can live in different security domains, which is what makes MFAaaS possible.