You are viewing an old version of this page. View the current version.
Compare with Current
View Page History
Version 1
Next »
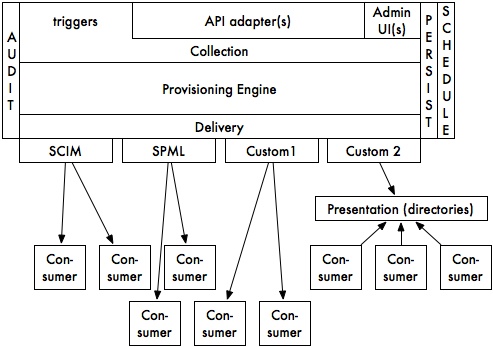
|
- Data enters the Provisioning Engine in one of three primary ways – "pushed" into the provisioning interface via a trigger (or other mechanism) fired from the layer above (presumed to be one of the IdM registries), "pushed" into the provisioning interface via an administrative UI (for use by administrators in manually "forcing" provisioning actions to occur), or through a set of adapter API routines designed to allow the provisioning engine itself to retrieve data from the layer above (eg., in the event that completing a provisioning task started by a trigger from an IdM registry requires access to other data in the same or a different registry). It is the responsibility of the "Collection" layer and its associated modules to manage the interface between the registries and the Provisioning Engine, and to marshal and collect the information required by the Provisioning Engine.
- The provisioning engine in turn is responsible for applying business logic, including attribute access controls, attribute transformations, and dependency computations.
- The Delivery layer is then responsible for taking the finalized output of the provisioning engine and, based on pre-arranged subscription information, selecting particular consumers and their associated delivery mechanisms and triggering them to provision data (according to their own configuration and protocol specifications) to consumer systems.
- The Delivery layer relies on a collection of protocol- and/or consumer-specific modules to actually drive its provisioning efforts. Multiple consumers may use the same delivery protocol module (eg., SCIM may be used to provision into more than one consumer) but multiple protocol modules may be used by multiple different consumers.
- A special case collection of consumers are the presentation layer interfaces (eg., directories). Provisioning into those consumers is not typically performed for their own purposes, but in order to allow still other, secondary consumers to access the provisioned information via "pull" methods (eg., via LDAP). Some consumers may also use custom APIs to directly "pull" data directly from the IdM registries (much as the API adapters associated with the provisioning engine's collection layer do) but those are not considered in-scope in this diagram).
- All layers of the provisioning stack are responsible for interacting with an audit logging interface, whose responsibility is to build and maintain audit trails suitable for debugging as well as reporting on the history of data passed through the provisioning stack.
- The stack includes persistence and scheduling mechanisms in support of time-dependent provisioning operations (eg. to support a rule of the form "all terminated employees' "employee" affiliations should be removed at the time of termination, and their electronic mailboxes and Kerberos principals should be disabled 14 days following their termination). The same persistence mechanism might also be used to support "retry-on-failure" options (eg., if a triggered event cannot be processed immediately due to a failure in the consumer system or in the network between the provisioning system and the consumer, the event might be queued and retried on some fixed schedule some number of times before being completely dropped).
|