Terminology:
- "data field" is a user attribute, do not want use attribute since it overlaps with attribute framework
This is a suggestion for how user data could flow to Grouper in future state
The problem this is trying to solve
- User data in subjects, provisioners, and loaders solve similar problems
- Real time data solved in multiple ways
- Security of who is allowed to see what (by person aka row or data field aka value)
- Efficiency of being able to query data without reaching out to other resources
- Ability to use data from multiple sources at one time
- Reduce the number of network calls in various places
- Reduce the SQL and LDAP syncs required to make things work
- Troubleshooting access is difficult when the history of data field changes is not known
- Unresolvable subjects are a pain... history of data fields of users will help
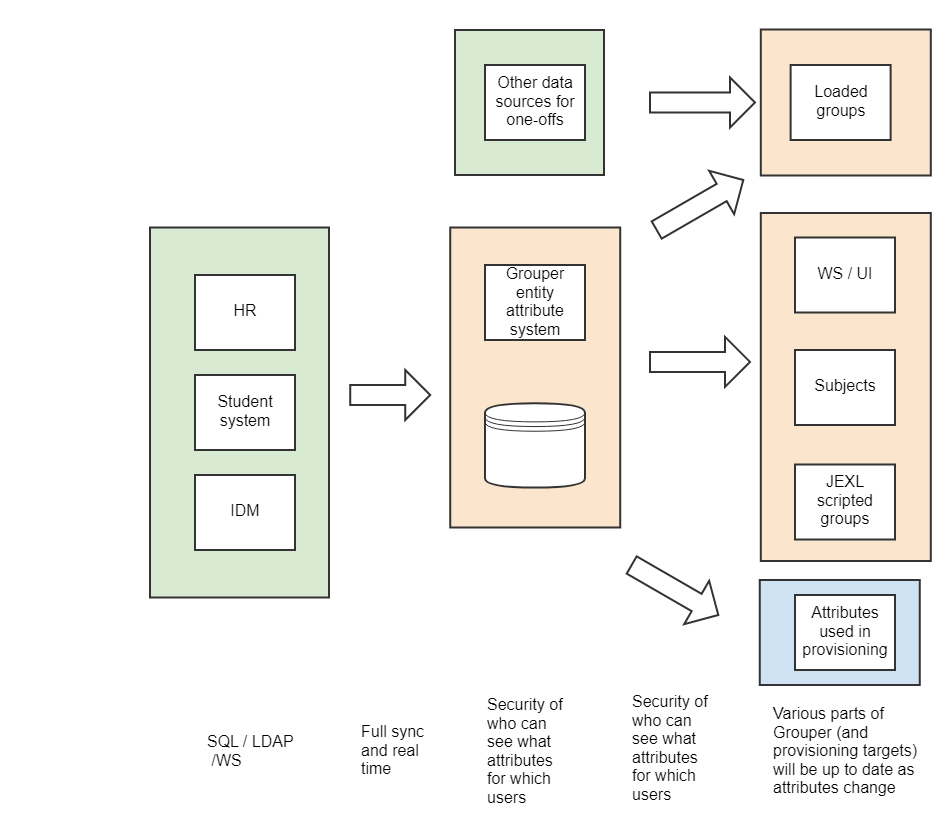
Setup entity resolvers
The first configuration step is to set up entity resolvers
For users
- SQL queries
- LDAP filters
- WS calls
Returns
- Single valued data fields for users
- Returns multi-valued data fields for users
- Multivalued rows of data fields for users (e.g. affiliation rows that have affiliation and dept)
Two types of data fields
- Informational
- e.g. name, description, email, etc
- Needed for provisioning or UI or WS
- Access related
- e.g. dept, title, school, DN
- Needed for loading groups, jexl scripted groups, provisioning events
Point in time
- Grouper can store point in time information about data fields
Assumption
All institutions are either
- OK with full sync of user data fields on a schedule and thats how up to date they are (e.g. every 30 minutes, hourly, daily)
- or: Can get events of when data changes in source systems
- or: Queries to source systems have last updated dates or change logs for real time updates
Grouper gets that data
- Copies to Grouper database
- Could process the data a tad
- "Virtual data fields" can have logic and make a complicated description data field (across multiple resolver sources)
- Its possible that this could help the problem of having too many subject sources though this isn't intended to be an identity system
- Can assign security so Grouper knows who is allowed to read which data
- Each data field could have a group assigned who can see the data
- There are real time events or timestamps that ensures data is up to date
Subject source
- Points to Grouper's database
- Instead being configured against source would be configured against entity resolver data
- Can use data from multiple sources
- Note, if entity resolver data is secure and available over UI/WS then the subject doesnt need as many fields... e.g. Penn would not need first name and last name etc.
- Subject could just be id
- People who are allowed to see various entity resolver data fields would see description a certain way, name a certain way, and whatever data fields they can see when they need it
- Imagine a more detailed subject page for people who can see the data... easier to troubleshoot access
- Points to Grouper's database
Members table
- Members table can be stripped down since data is in the entity tables
Loaders
- Loaders and jexl scripted groups can be written on top of entity data
- Non admins can securely use that data since Grouper knows who is allowed to see what
- When the entity resolver knows that data changed real-time, it knows which loader/jexl scripted group to update
- Not all data about users will be entity resolvers... more than what was in subject source, but not everything
- If there is peripheral data you can make SQL/LDAP loaders for that
- Privileges for loaded groups could be loaded with users who can see all the related data fields
UI/WS
- Imagine more data fields than subject data fields available over WS/UI securely in one query
Provisioning
- No more "subject link"
- You can provision any entity resolver data easily
- When data changes, Grouper can tell a provisioner to recalc a user
Summary
In summary here is a metaphor... we used to have SQL credentials in multiple places, then we made an external system layer to re-use that. This suggested is similar. Have a data layer that can we re-used across things. Includes real-time updates, security, and data manipulation configured centrally... why? if we want to be ABAC and data field-based, we need to organize our data fields