The goal of this project is to centrally collect TIER data about Grouper deployment to help improve Grouper and give information to TIER constituents about Grouper usage.
- Grouper has a central database which can store information for a Grouper env at an institution
- Each JVM process (API, WS, UI, Daemon, GSH, etc) can periodically check in to the DB (e.g. every 6 hours)
- Let it know its UUID, type of process, number of tx of various types since last checkin, version, patch level, uptime
- Daily a new instrumentation daemon could collate information in the database, and glean other information (e.g. is PSP or PSPNG running) and after consulting the discovery service, send a report to the TIER collector
Discovery service
- Simple static HTTP resource(s) that would be always/forever available (e.g. hosted at AWS?) to designate where the TIER collector(s) are
-
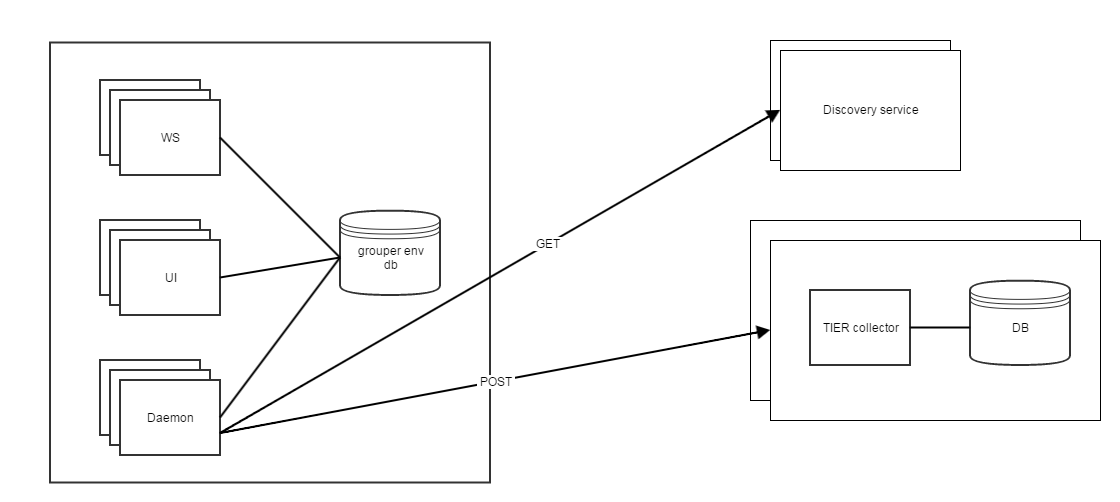 Note, we can start out with one collector. Client failover is optional, the first endpoint might be used only for simple clients
Note, we can start out with one collector. Client failover is optional, the first endpoint might be used only for simple clients - e.g. request: GET (current)
- e.g. request: GET (outdated)
{
serviceEnabled: true,
endpoints: [
{
uri: "https://grouperdemo.internet2.edu/tierInstrumentationCollector/tierInstrumentationCollector/v1/upload"
},
{
uri: "https://grouperdemo2.internet2.edu/tierInstrumentationCollector2/tierInstrumentationCollector/v1/upload"
}
]
}
Collector
- Simple REST endpoint that takes any name/value pairs in JSON in a simple structure of single valued strings
- The collector can just store each resource it gets and doesnt care what the attributes are, so the components can change their data as they need
- Of course the reporting and processing needs to take the attributes and values into account
- e.g. submission: POST https://tiercollector1.internet2.edu/v1/collector/dailyReport
{
reportFormat: 1,
component: "grouper",
institution: "Penn",
environment: "prod",
version: "2.3.0",
patchesInstalled: "api1, api2, api4, ws2, ws3",
wsServerCount: 3,
platformLinux: true,
uiServerCount: 1,
pspngCount: 1,
provisionToLdap: true,
registrySize: 12345678,
transactionCountMemberships: 12432,
transactionCountPrivileges: 432,
transactionCountPermissions: 17
}
Schema on mysql (record table and attribute table)
Note: diagnostics should take into account generic daemon configs
Enable collection
Get patches for 2.3 (24 and 25)
Set this in grouper-loader.properties
otherJob.tierInstrumentationDaemon.class = edu.internet2.middleware.grouper.instrumentation.TierInstrumentationDaemon otherJob.tierInstrumentationDaemon.quartzCron = 0 0 2 * * ?
Collecting UI Counts (under development)
- Data will be kept in the folder etc:attribute:instrumentationData
- Collect counts of servlet requests, group adds/deletes, membership adds/deletes, folders adds/deletes
- UI can start a new thread when the servlet first initializes
- The new thread (a single thread executor) will enable stat collection (i.e. set some static variable)
- Grouper api and ui code will update various static lists of timestamps indicating when each operation is done
- A config option will determine how often the thread will go through the timestamps in memory and update the grouper database. Lower means fewer gaps when the process is killed.
- Another config option will specify the increments to keep counts of. E.g. if we're keeping counts by 10 minutes or hour or day.
- When the UI thread starts up, check to see if an "<ENGINE_NAME>_instrumentation.dat" file exists in the logs directory. This file will contain the uuid of this instance.
- If it doesn't exist, create it and create a corresponding attribute in grouper, e.g. etc:attribute:instrumentationData:instrumentationDataInstances:theuuid (def = etc:attribute:instrumentationData:instrumentationDataInstancesDef)
- The <ENGINE_NAME>_instrumentation.dat file should have a trivial update whenever the thread flushes to the database just in case the system is cleaning old files.
- There will be a group used for assignments - etc:attribute:instrumentationData:instrumentationDataInstancesGroup.
- There will be a single assign multi valued attribute - etc:attribute:instrumentationData:instrumentationDataInstanceCounts (def = etc:attribute:instrumentationData:instrumentationDataInstanceCountsDef)
- There will also be other attributes (def = etc:attribute:instrumentationData:instrumentationDataInstanceDetailsDef) - etc:attribute:instrumentationData:instrumentationDataInstanceLastUpdate, etc:attribute:instrumentationData:instrumentationDataInstanceEngineName, etc:attribute:instrumentationData:instrumentationDataInstanceServerLabel
- So etc:attribute:instrumentationData:instrumentationDataInstances:theuuid will be assigned to etc:attribute:instrumentationData:instrumentationDataInstancesGroup. And on that assignment will live assignments with actual data (instrumentationDataInstanceCounts, instrumentationDataInstanceLastUpdate, instrumentationDataInstanceEngineName, instrumentationDataInstanceServerLabel)
The value of the assignment on the assignment (instrumentationDataCounts) will be like:
{"startTime" : 1486753200000, "duration" : 600000, "UI_REQUESTS" : 30, "API_GROUP_ADD" : 5, "API_GROUP_DELETE" : 3}There may be multiple values added each time it runs. For example, if the database is updated every hour and the increment is every 10 minutes, then it could add 6 of these.
{"startTime" : 1486753200000, "duration" : 600000, "UI_REQUESTS" : 30, "API_GROUP_ADD" : 5, "API_GROUP_DELETE" : 3} {"startTime" : 1486753800000, "duration" : 600000, "UI_REQUESTS" : 300, "API_GROUP_ADD" : 2, "API_GROUP_DELETE" : 6} {"startTime" : 1486754400000, "duration" : 600000, "UI_REQUESTS" : 3000, "API_GROUP_ADD" : 1, "API_GROUP_DELETE" : 2}etcThe TIER instrumentation daemon will sends these to TIER.
"instances" : [ { "uuid" : "uuid1", "engineName" : "grouperUI", "serverLabel" : "ui-01" "lastUpdate" : 1488825739828, "newCounts" : [{"startTime" : 1486753200000, "duration" : 600000, "UI_REQUESTS" : 30, "API_GROUP_ADD" : 5, "API_GROUP_DELETE" : 3}, {"startTime" : 1486753800000, "duration" : 600000, "UI_REQUESTS" : 300, "API_GROUP_ADD" : 2, "API_GROUP_DELETE" : 6}, {"startTime" : 1486754400000, "duration" : 600000, "UI_REQUESTS" : 3000, "API_GROUP_ADD" : 1, "API_GROUP_DELETE" : 2}] }, { "uuid" : "uuid2", "serverLabel" : "ui-02" "engineName" : "grouperUI", "lastUpdate" : 1488825739829 }, { "uuid" : "uuid3", "serverLabel" : "ws-01" "engineName" : "grouperWS", "lastUpdate" : 1488825739829 }, { "uuid" : "uuid4", "serverLabel" : "ws-02" "engineName" : "grouperWS", "lastUpdate" : 1488825739829 }, { "uuid" : "uuid5", "serverLabel" : "daemon-01" "engineName" : "grouperLoader", "lastUpdate" : 1488825739829 } ]An attribute will be created for each collector (e.g. etc:attribute:instrumentationData:instrumentationDataCollectors:OTHER_JOB_tierInstrumentationDaemon). This will be assigned to another group (etc:attribute:instrumentationData:instrumentationDataCollectorsGroup). And that assignment will have the time the collector was last updated (etc:attribute:instrumentationData:instrumentationDataCollectorLastUpdate).
The values won't be audited (user audit or point in time audit)
- The cleanLogs daemon will delete counts older than 30 days (configurable).
- Code should be reusable for WS, loader, etc.
Notes
- Keith is interested in LogStash
- Scott is interested in Metrics (java library)