...
- Sync memberships to their own table for performance reasons (when you are doing reporting and have a lot of joins and subselects, a table without lots of joins can help a lot)
- Sync memberships to another database. Other applications might not want to depend on Grouper at runtime, or have other performance reasons
- Sync a subject table from another database to Grouper. This might be for performance or availability reasons
- Sync some table to another table. This function is generic so use it for whatever you want (groups, attributes, etc)
The tables in the "from" and "to" need to exist and the right columns and column types need to be there. In addition you cannot name columns which are keywords in our database.
Currently this only works in full sync mode. Real time incremental updates will be added soon.
...
- Make a view with the data you want to sync
- This can be based on some ad hoc groups, folders, or attributes on groups
- For instance this could be the view
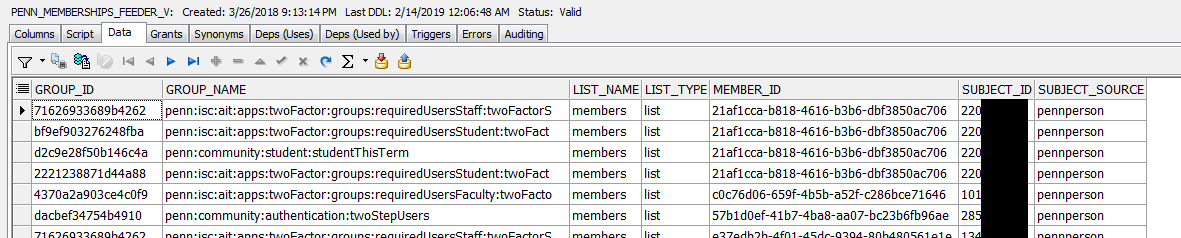
This view is defined (oracle) as:
Code Block /* Formatted on 5/1/2019 11:27:03 AM (QP5 v5.252.13127.32847) */ CREATE OR REPLACE FORCE VIEW PENN_MEMBERSHIPS_FEEDER_V ( GROUP_ID, GROUP_NAME,LIST_NAME, LIST_TYPE, MEMBER_ID, SUBJECT_ID, SUBJECT_SOURCE ) BEQUEATH DEFINER AS SELECT GROUP_ID, group_name, list_name, GMLV.LIST_TYPE, GMLV.MEMBER_ID, GMLV.SUBJECT_ID, GMLV.SUBJECT_SOURCE FROM grouper_memberships_lw_v gmlv WHERE ( GMLV.GROUP_NAME IN ('penn:community:student:studentThisTerm', 'penn:community:student:degreePursual:degreePursual_LLM', ... ) OR gmlv.group_name LIKE 'penn:isc:ait:apps:atlassian:%') AND GMLV.SUBJECT_SOURCE = 'pennperson' AND list_type = 'list';Configure databases in grouper.client.properties. Note, the "id" of the config group is the part of the config that ties them together, e.g. "pcom" or "awsDev"
Code Block grouperClient.jdbc.pcom.driver = oracle.jdbc.driver.OracleDriver grouperClient.jdbc.pcom.url = jdbc:oracle:thin:@(DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = ... grouperClient.jdbc.pcom.user = myuser grouperClient.jdbc.pcom.pass = ****** grouperClient.jdbc.awsDev.driver = org.postgresql.Driver grouperClient.jdbc.awsDev.url = jdbc:postgresql://penn ... grouperClient.jdbc.awsDev.user = anotheruser grouperClient.jdbc.awsDev.pass = ******
Note, you can use the grouper database like this (in grouper.client.properties)
Code Block grouperClient.jdbc.grouper.driver.elConfig = ${edu.internet2.middleware.grouper.cfg.GrouperHibernateConfig.retrieveConfig().propertyValueString("hibernate.connection.driver_class")} grouperClient.jdbc.grouper.url.elConfig = ${edu.internet2.middleware.grouper.cfg.GrouperHibernateConfig.retrieveConfig().propertyValueString("hibernate.connection.url")} grouperClient.jdbc.grouper.user.elConfig = ${edu.internet2.middleware.grouper.cfg.GrouperHibernateConfig.retrieveConfig().propertyValueString("hibernate.connection.username")} grouperClient.jdbc.grouper.pass.elConfig = ${edu.internet2.middleware.grouper.cfg.GrouperHibernateConfig.retrieveConfig().propertyValueString("hibernate.connection.password"hibernate.connection.password")}You can do a loader config database like this:
Code Block grouperClient.jdbc.pcom2.driver.elConfig = ${edu.internet2.middleware.grouper.app.loader.GrouperLoaderConfig.retrieveConfig().propertyValueString("db.pcom2.driver")} grouperClient.jdbc.pcom2.url.elConfig = ${edu.internet2.middleware.grouper.app.loader.GrouperLoaderConfig.retrieveConfig().propertyValueString("db.pcom2.url")} grouperClient.jdbc.pcom2.user.elConfig = ${edu.internet2.middleware.grouper.app.loader.GrouperLoaderConfig.retrieveConfig().propertyValueString("db.pcom2.user")} grouperClient.jdbc.pcom2.pass.elConfig = ${edu.internet2.middleware.grouper.app.loader.GrouperLoaderConfig.retrieveConfig().propertyValueString("db.pcom2.pass")}Configure the table sync in grouper.client.properties
Code Block # grouper client database key where copying data from # {valueType: "string"} grouperClient.syncTable.memberships.databaseFrom = pcom # if using a different schema than the connecting schema # {valueType: "string"} grouperClient.syncTable.memberships.schemaFrom = # table or view where copying data from # {valueType: "string"} grouperClient.syncTable.memberships.tableFrom = PENN_MEMBERSHIPS_FEEDER_V # grouper client database key where copying data to # {valueType: "string"} grouperClient.syncTable.memberships.databaseTo = awsDev # if using a different schema to copy data to # {valueType: "string"} grouperClient.syncTable.memberships.schemaTo = # table or view where copying data to # {valueType: "string"} grouperClient.syncTable.memberships.tableTo = PENN_MEMBERSHIPS_TEMP # columns must match in from and to tables, you can specify columns or do all with an asterisk # {valueType: "string"} grouperClient.syncTable.memberships.columns = * # if there is a primary key, list it, else list the composite keys # {valueType: "string"} grouperClient.syncTable.memberships.primaryKeyColumns = group_id, list_name, member_id # the grouping column is what is uniquely selected, and then batched through to get data. # {valueType: "string"} grouperClient.syncTable.memberships.groupingColumn = group_id # the grouping column is what is uniquely selected, and then batched through to get data, defaults to 10000 # {valueType: "integer"} grouperClient.syncTable.memberships.groupingSize = 5Setup an other job to run this in grouper-loader.properties
Code Block # Object Type Job class # {valueType: "class", mustExtendClass: "edu.internet2.middleware.grouper.app.loader.OtherJobBase", mustImplementInterface: "org.quartz.Job"} otherJob.membershipSync.class = edu.internet2.middleware.grouper.app.tableSync.TableSyncOtherJob # Object Type Job cron # {valueType: "string"} otherJob.membershipSync.quartzCron = 0 0/30 * * * ? # this is the key in the grouper.client.properties that represents this job otherJob.membershipSync.grouperClientTableSyncConfigKey = memberships # full or incremental # {valueType: "string"} otherJob.membershipSync.syncType = full
Performance
The performance will be limited by how many changes there are and how quickly it can get the data on both sides.
...
- Setup view.

- Setup databases in grouper.client.properties (see memberships example)
Configure the table sync in grouper.client.properties
Code Block # grouper client database key where copying data from # {valueType: "string"} grouperClient.syncTable.personSource.databaseFrom = pcom # if using a different schema than the connecting schema # {valueType: "string"} grouperClient.syncTable.personSource.schemaFrom = # table or view where copying data from # {valueType: "string"} grouperClient.syncTable.personSource.tableFrom = PERSON_SOURCE # grouper client database key where copying data to # {valueType: "string"} grouperClient.syncTable.personSource.databaseTo = awsDev # if using a different schema to copy data to # {valueType: "string"} grouperClient.syncTable.personSource.schemaTo = # table or view where copying data to # {valueType: "string"} grouperClient.syncTable.personSource.tableTo = PERSON_SOURCE_TEMP # columns must match in from and to tables, you can specify columns or do all with an asterisk # {valueType: "string"} grouperClient.syncTable.personSource.columns = * # if there is a primary key, list it, else list the composite keys # {valueType: "string"} grouperClient.syncTable.personSource.primaryKeyColumns = penn_id # the grouping column is what is uniquely selected, and then batched through to get data. # {valueType: "string"} grouperClient.syncTable.personSource.groupingColumn = penn_id # the grouping column is what is uniquely selected, and then batched through to get data, defaults to 10000 # {valueType: "integer"} grouperClient.syncTable.personSource.groupingSize = 10000 # size of jdbc batches # {valueType: "integer"} grouperClient.syncTable.personSource.batchSize = 50 # column of date or timestamp which is last updated of row # {valueType: "string"} grouperClient.syncTable.personSource.realTimeLastUpdatedCol = last_updated # database which holds table to keep status of real time and full sync # {valueType: "string"} grouperClient.syncTable.personSource.statusDatabase = awsDev # schema of status table if different than connecting schema # {valueType: "string"} grouperClient.syncTable.personSource.statusSchema = # table of status where real time and full sync status is # {valueType: "string"} grouperClient.syncTable.personSource.statusTable = grouper_chancechange_log_consumer # if doing real time and nightly full sync, this is the hour where full sync should start # {valueType: "integer"} grouperClient.syncTable.personSource.fullSyncHourStart = 3 # if doing real time and nightly full sync, this is the hour where full sync should have already started # {valueType: "integer"} grouperClient.syncTable.personSource.fullSyncHourEnd = 4Setup an other job to run this in grouper-loader.properties
Code Block # Object Type Job class # {valueType: "class", mustExtendClass: "edu.internet2.middleware.grouper.app.loader.OtherJobBase", mustImplementInterface: "org.quartz.Job"} otherJob.personSourceSync.class = edu.internet2.middleware.grouper.app.tableSync.TableSyncOtherJob # Object Type Job cron # {valueType: "string"} otherJob.personSourceSync.quartzCron = 0 * * * * ? # this is the key in the grouper.client.properties that represents this job otherJob.personSourceSync.grouperClientTableSyncConfigKey = personSource