As we move towards migrating our Shibboleth IdPs to Amazon Web Services, we have an even greater need to remove its dependency on multiple LDAPs and consolidate all necessary user data to the Active Directory. In addition, as we implement Grouper as the central authorization management tool, we need to ensure that PII is available for authorized applications and units to consume, in order to provide the same user experience regardless of data suppression. Because our AD is a critical component of so many services across campus, it made sense to provide greater functionality and greater security for the good of our campus.
The University of Illinois at Urbana-Champaign has historically maintained two LDAP instances that served slightly different flavors of directory information. One LDAP instance (what we call the Campus LDAP) contains all user attributes with access restrictions on sensitive data classes, while our Active Directory LDAP contains somewhat of a "redacted" identity for those users with FERPA-protected attributes. These redacted identities in AD have no personally identifiable information (PII); this was accomplished by suppressing several personal name attributes (givenName, sn, etc.) in AD by replacing them with null values or a NetID (our name for the logon ID). This has proven to be a poor experience for both the user as well as for units and applications that provide IT services to those users.
In order to eliminate duplication and also provide the best of both LDAPs, our Identity and Access Management team decided to keep the Active Directory and retire the Campus LDAP. This meant that we would need to converge all of the existing attributes and ensure that sensitive data on FERPA-protected users was readily available in the AD, without compromising access controls on those attributes. The solution we arrived at was to create a set of "shadow" attributes that contained all of the PII, while placing them in a custom property set, protected with privileged access. This solution perpetuates the redaction of PII from default attributes that are accessible to the general authenticated public, while providing service accounts and applications the necessary privileged access to the real data. It also requires zero touch by current services-- they can continue to consume the same data as they are used to now without any changes, or they can opt to apply for the privilege to access the protected attributes.
UMBC has been using a custom IDMS system since 2002. Over the years it has grown quite extensive, so replacing it is no small matter. We are looking to use MidPoint as a replacement, and my desire is to avoid a large "switchover date". Instead replacing pieces as they become available. To this end I've decided to start with two functions that are relatively isolated and can also be greatly improved by transitioning to MidPoint. The first is UMBC's account provisioning engine. It seems like a good candidate because it is a currently a single standalone process that could use a rewrite to improve its robustness, logging, and modularity.
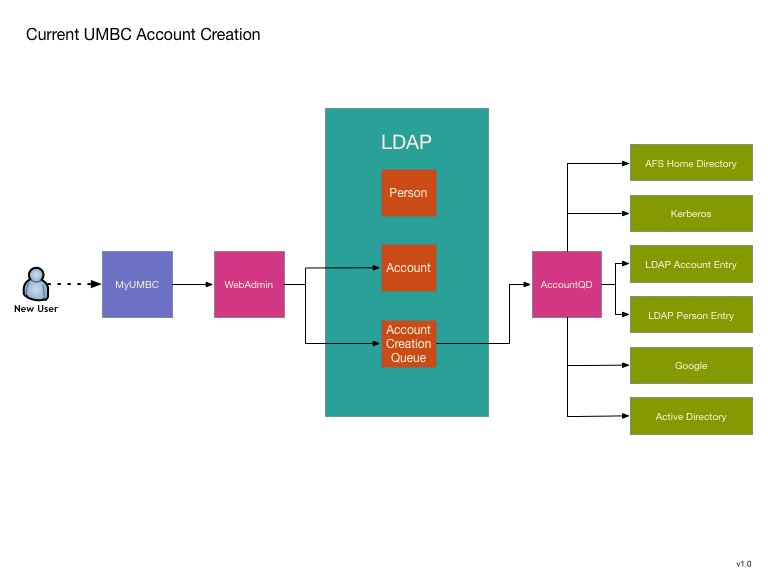
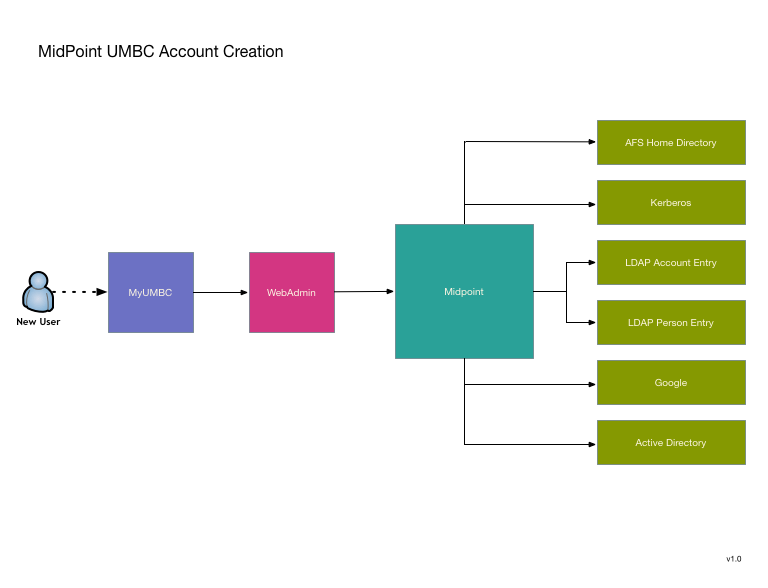
Transitioning to MidPoint will not substantially change the model, but will offer allow MidPoint's improvements without reliance on major shim code writing that will have to be replaced as we do additional migrations toward total conversion to MidPoint.
The second function that appears to be a good candidate is UMBC's guest account request system. Currently there really isn't one, or rather there are four completely different systems that combine to cover most of the use cases. These could all use improvement and I think that a unified conversion to MidPoint will allow improvements as well as a workflow simplification.
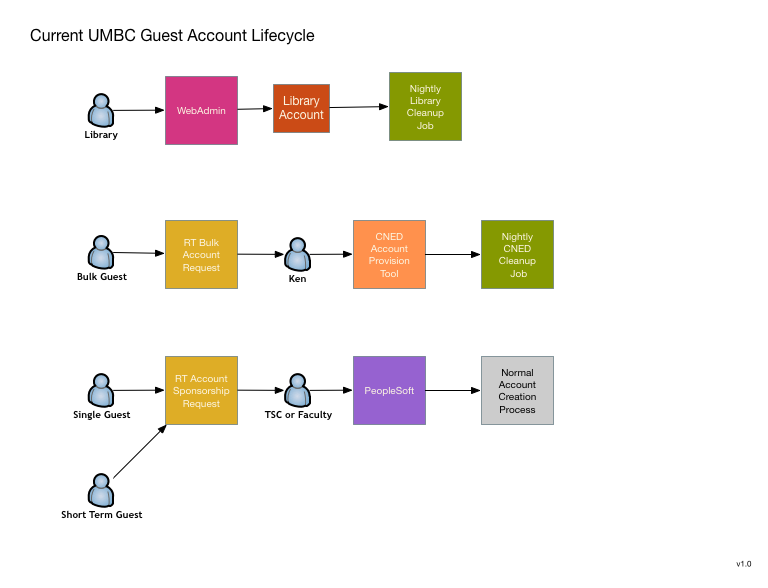

This is primarily a request system, although some of the current systems do perform their own provisioning and de-provisinioning within a limited scope. It is still unclear to what extend MidPoint can be used as an end user request or approver UI. If it is unable to be used in this way, I'm looking at using possibly using CoManange to perform these UI functions rather than writing something myself.
We had four attendees at the Face2Face Meeting, Randy Miotke and Jeff Ruch are our technical team members, Scott Baily our campus lead, and Dave Hoffman from project management. Our entire group found the experience very worthwhile and came back with a lot of positive feedback.
Our technical team, through discussion and presentations, are now looking to use COmanage as the source of record for the external to CSU population and then provision to midPoint registry. We will use midPoint as the primary entity registry and leverage its provisioning capabilities. They both appreciated the Grouper office hours that were provided as several items that they were struggling with were resolved on-site.
From a project management perspective, developing networking with other institutions and discussing common issues was important. Moving forward, collaboration around how to better engage and work with vendors is something that needs to continue. Along with our technical team, he found that discussion regarding implementation plans around Midpoint and sharing of project plans will be invaluable as we begin looking at this process.
Our team at CSU is in the final stages of implementing COmanage for use as an entity registry with account linking capabilities for use with our department of University Advancement’s Donor Connect system. Here’s how it will work:
A user will go to the Advancement website to access the Donor Connect system; this is our first service provider where we will be implementing this process and there is interest from other departments and system for future expansion. The user will be given options of logging in with the CSU Identity Provider or if the user is not affiliated with CSU another discovery service like Google, Facebook, MSN, etc. Once they select the system they prefer, they will be redirected to that site for authentication. Upon successful login to that system and permission has been granted to share account information with the service provider the Social to SAML gateway will route them back to the Donor Connect page.
At this point, our system will look for a match in our LDAP directory; if there is no match, the user will be put through a verification process. Once they have been verified their information will be logged in COmanage. If the user is already affiliated with CSU they will be in the registry from the data load from our internal HR and Student systems. We will then have both internal and external records in the COmanage Registry.
It will create a unique ID that ties multiple accounts to one person for a quicker authorization process for future access. There is a provisioning process set up to send COmanage person and identity data to the LDAP directory in order for it to be logged and a match to be found the next time a user logs in. There is also a provision in Grouper that sends group data which is also pulled from our internal CSU systems to the LDAP directory.
As of today, person data from CSU systems has been loaded into COmanage and group data has been loaded into Grouper. COmanage and LDAP have production instances in place and the Grouper production instance is being finalized based on deployment guidelines. After this project launches our team will look at containerized versions.