This example is of a person feed. The feed needs to go from an IDM database to a Banner database for a list of users and attributes (some from Grouper).
Setup a view, have a where clause that constrains by a group (note, you can provision Grouper memberships to the IDM database with a different SQL sync).
CREATE OR REPLACE FORCE VIEW VIEW_WITH_PEOPLE_V
(
PENN_ID
)
BEQUEATH DEFINER
AS
SELECT subject_id AS penn_id
-- table provisioned from grouper which is like grouper_memberships_lw_v
FROM penn_memberships_lw gmlv
WHERE gmlv.subject_source = 'pennperson'
-- policy group that
AND gmlv.group_name = 'a:b:c:somePolicyGroup'
AND gmlv.list_name = 'members';
This is the view we will sync
CREATE OR REPLACE FORCE VIEW SOME_VIEW_V
(
employee_ID,
GUID,
LAST_NAME,
FIRST_NAME,
MIDDLE_NAME,
NAME_PREFIX,
NAME_SUFFIX,
EMAIL_ADDRESS,
STREET1,
STREET2,
STREET3,
CITY,
STATE,
POSTAL_CODE,
PHONE_NUMBER,
EXTENSION,
ALL_ACTIVE_AFFILIATIONS,
ORG,
TITLE,
DESCRIPTION,
LAST_UPDATED
)
BEQUEATH DEFINER
AS
SELECT cp.id, cp.guid, ...
FROM COMPUTED_PERSON cp,
VIEW_WITH_PEOPLE_V vwpv
WHERE cp.char_penn_id = vwpv.PENN_ID;
GRANT SELECT ON VIEW SOME_VIEW_V TO AUTHZADM;
Create a table in a database to sync from, either you need to create explicitly, or if its the same database or a database with a dblink, you can have the database create it for you
create table SOME_TABLE as (select * from SOME_VIEW_V where 1!=1);
Now we need to decide which types of SQL sync we will use. Lets try a few of them and see how they do with performance. Start with a full sync full. We need the databases, tables, columns, and primary key
grouper.client.properties
# grouper client or loader database key where copying data from grouperClient.syncTable.some_view.databaseFrom = myDb # table or view where copying data from, include the schema if needed grouperClient.syncTable.some_view.tableFrom = pcdadmin.some_view_v # grouper client or loader database key where copying data to grouperClient.syncTable.some_view.databaseTo = anotherDb # table or view where copying data to, include the schema if needed grouperClient.syncTable.some_view.tableTo = some_schema.some_Table # columns must match in from and to tables, you can specify columns or do all with an asterisk grouperClient.syncTable.some_view.columns = * # if there is a primary key, list it, else list the composite keys. note, this doesnt # have to literally be the database prmiary key, just need to be a unique col(s) in table grouperClient.syncTable.some_view.primaryKeyColumns = employee_id
fullSyncFull
Now lets setup the full sync and run one.
grouper-loader.properties
# Object Type Job class otherJob.some_view_full.class = edu.internet2.middleware.grouper.app.tableSync.TableSyncOtherJob # Object Type Job cron otherJob.some_view_full.quartzCron = 0 0 5 * * ? # this is the key in the grouper.client.properties that represents this job otherJob.some_view_full.grouperClientTableSyncConfigKey = some_view # fullSyncFull, fullSyncGroups, fullSyncChangeFlag, incrementalAllColumns, incrementalPrimaryKey otherJob.some_view_full.syncType = fullSyncFull
You need to start a loader to schedule this. I will just start one from command line, then kill it
gsh -loader
Run it manually from the UI, and it runs for a while. Run it a second time and it runs for 1.2 million records in just under 4 minutes. It does use a lot of memory to get both datasets in memory at one time.
2020-02-13 21:19:24,769: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: retrieveData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncFull, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581646699935 2020-02-13 21:20:24,987: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: retrieveData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncFull, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581646699935 2020-02-13 21:21:25,250: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: retrieveData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncFull, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581646699935 2020-02-13 21:22:01,757: [main] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: true, state: done, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncFull, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581646699935, retrieveDataFromCount: 1290590, retrieveDataFromMillis: 184418, retrieveDataToCount: 1290590, retrieveDataToMillis: 206597, deletesCount: 0, deletesMillis: 0, insertsCount: 0, insertsMillis: 0, updatesCount: 74, updatesMillis: 53, queryCount: 11, tookMillis: 217202, took: 0:03:37.202
Here is an example final log of updating 400k records. This is essentially 130k updates per minute (since this took 6.5 minutes, instead of 3.5 minutes)
finalLog: true, state: done, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncFull, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581644355937, retrieveDataFromCount: 1290590, retrieveDataFromMillis: 182013, retrieveDataToCount: 1290590, retrieveDataToMillis: 202774, deletesMillis: 0, insertsMillis: 0, updatesCount: 390847, updatesMillis: 180620, queryCount: 519, tookMillis: 394049, took: 0:06:34.049
fullSyncGroupings
We can set the primary key col (since there is one col primary key) as the grouping col. This will select all groupings from one side and the other, sort them, do the inserts/deletes, then select swaths of groupings of 100k records with one query. This is a full sync but is more efficient and doesnt use as much memory
grouper.client.properties
# the grouping column is what is uniquely selected, and then batched through to get data. Optional.
# for groups this should be the group uuid
# {valueType: "string"}
# grouperClient.syncTable.some_view.groupingColumn = employee_id
# the grouping column is what is uniquely selected, and then batched through to get data, defaults to global setting
# {valueType: "integer"}
# grouperClient.syncTable.some_view.groupingSize = 100000
grouper-loader.properties
# fullSyncFull, fullSyncGroups, fullSyncChangeFlag, incrementalAllColumns, incrementalPrimaryKey otherJob.some_view_full.syncType = fullSyncGroups
This took 6 minutes for 1.3 million rows. Here are example logs. Note, before the final log, the times are in micros and not millis to be more precise
2020-02-13 21:06:48,480: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: retrieveData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncGroups, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581645944789, retrieveGroupsToCount: 1290590, retrieveGroupsToMillis: 18782610 2020-02-13 21:07:48,574: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: retrieveData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncGroups, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581645944789, retrieveGroupsToCount: 1290590, retrieveGroupsToMillis: 18782610 2020-02-13 21:08:48,914: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: syncData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncGroups, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581645944789, retrieveGroupsToCount: 1290590, retrieveGroupsToMillis: 18782610, retrieveGroupsFromCount: 1290590, retrieveGroupsFromMillis: 147822470, deleteGroupingsCount: 0, deleteGroupingsGroupsCount: 0, deleteGroupingsMillis: 46, retrieveDataToCount: 100000, retrieveDataToMillis: 19050025, retrieveDataFromCount: 100000, retrieveDataFromMillis: 23414151, deletesCount: 0, deletesMillis: 13, insertsCount: 0, insertsMillis: 13, updatesCount: 0, updatesMillis: 12 2020-02-13 21:09:48,987: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: syncData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncGroups, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581645944789, retrieveGroupsToCount: 1290590, retrieveGroupsToMillis: 18782610, retrieveGroupsFromCount: 1290590, retrieveGroupsFromMillis: 147822470, deleteGroupingsCount: 0, deleteGroupingsGroupsCount: 0, deleteGroupingsMillis: 46, retrieveDataToCount: 400000, retrieveDataToMillis: 75379944, retrieveDataFromCount: 400000, retrieveDataFromMillis: 68221662, deletesCount: 0, deletesMillis: 58, insertsCount: 0, insertsMillis: 51, updatesCount: 0, updatesMillis: 59 2020-02-13 21:10:49,270: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: syncData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncGroups, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581645944789, retrieveGroupsToCount: 1290590, retrieveGroupsToMillis: 18782610, retrieveGroupsFromCount: 1290590, retrieveGroupsFromMillis: 147822470, deleteGroupingsCount: 0, deleteGroupingsGroupsCount: 0, deleteGroupingsMillis: 46, retrieveDataToCount: 800000, retrieveDataToMillis: 142089149, retrieveDataFromCount: 800000, retrieveDataFromMillis: 126142709, deletesCount: 0, deletesMillis: 154, insertsCount: 0, insertsMillis: 98, updatesCount: 164, updatesMillis: 105758 2020-02-13 21:11:49,356: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: syncData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncGroups, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581645944789, retrieveGroupsToCount: 1290590, retrieveGroupsToMillis: 18782610, retrieveGroupsFromCount: 1290590, retrieveGroupsFromMillis: 147822470, deleteGroupingsCount: 0, deleteGroupingsGroupsCount: 0, deleteGroupingsMillis: 46, retrieveDataToCount: 1100000, retrieveDataToMillis: 187511824, retrieveDataFromCount: 1200000, retrieveDataFromMillis: 182821138, deletesCount: 0, deletesMillis: 191, insertsCount: 0, insertsMillis: 134, updatesCount: 164, updatesMillis: 105801 2020-02-13 21:12:05,001: [main] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: true, state: done, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncGroups, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581645944789, retrieveGroupsToCount: 1290590, retrieveGroupsToMillis: 18782, retrieveGroupsFromCount: 1290590, retrieveGroupsFromMillis: 147822, deleteGroupingsCount: 0, deleteGroupingsGroupsCount: 0, deleteGroupingsMillis: 0, retrieveDataToCount: 1290590, retrieveDataToMillis: 217165, retrieveDataFromCount: 1290590, retrieveDataFromMillis: 195605, deletesCount: 0, deletesMillis: 0, insertsCount: 0, insertsMillis: 0, updatesCount: 164, updatesMillis: 105, queryCount: 25, tookMillis: 376643, took: 0:06:16.643
fullSyncChangeFlag
This mode selects the primary keys and a change flag column (e.g. a last_updated col or a checksum col). This mode is not a real full sync, since if the change flag does not accurately reflect the data, then things can get missed. But if the change flag is accurate, then it should be fine. If you use this, you might want to do a fullSyncFull or a fullSyncGroups weekly. If you have a lot of large columns this is a more efficient sync mechanism.
grouper.client.properties
# if doing fullSyncChangeFlag (look for a col that says if the rows are equal, e.g. a timestamp or a checksum)
# {valueType: "string"}
grouperClient.syncTable.some_view.changeFlagColumn = last_updated
grouper-loader.properties
# fullSyncFull, fullSyncGroups, fullSyncChangeFlag, incrementalAllColumns, incrementalPrimaryKey otherJob.some_view_full.syncType = fullSyncChangeFlag
This took about 4 minutes for 1.3 million rows and used a lot less memory than the other full syncs. Here are example logs
2020-02-13 21:32:15,049: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: retrieveData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncChangeFlag, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581647463773 2020-02-13 21:33:15,266: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: retrieveData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncChangeFlag, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581647463773 2020-02-13 21:34:15,539: [Thread-13] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: false, state: retrieveData, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncChangeFlag, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581647463773 2020-02-13 21:35:11,493: [main] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: true, state: done, sync: sqlTableSync, provisionerName: personSourceProd, syncType: fullSyncChangeFlag, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, initialMaxProgressAllColumns: 1581647463773, retrieveChangeFlagFromCount: 1290590, retrieveChangeFlagFromMillis: 204685, retrieveChangeFlagToCount: 1290590, retrieveChangeFlagToMillis: 220549, deletesCount: 0, deletesMillis: 0, insertsCount: 0, insertsMillis: 0, selectAllColumnsCount: 110, selectAllColumnsMillis: 49, updatesCount: 110, updatesMillis: 52, queryCount: 12, tookMillis: 236604, took: 0:03:56.604
incrementalAllColumns
This mode is used when there are few deletes (e.g. a person table), and there is a flag in the data that is a timestamp or an increasing sequence integer. Records can be selected since the last update. Note, once you configure the column to check, you need to run a full sync job to initialize the grouper_sync table incremental_index or incremental_timestamp field, since the incremental sync will abort if the relevant field is empty.
grouper.client.properties
# name of a column that has a sequence or last updated date.
# must be in the main data table if incremental all columns
# {valueType: "string"}
# grouperClient.syncTable.some_view.incrementalAllColumnsColumn = last_updated
Run a full sync
See the incremental progress. Note it is correct, so we are good to go
select provisioner_name, incremental_index, incremental_timestamp from grouper_sync where provisioner_name = 'some_view'

grouper-loader.properties
# Object Type Job class otherJob.some_view_incremental.class = edu.internet2.middleware.grouper.app.tableSync.TableSyncOtherJob # Object Type Job cron otherJob.some_view_incremental.quartzCron = 0 * * * * ? # this is the key in the grouper.client.properties that represents this job otherJob.some_view_incremental.grouperClientTableSyncConfigKey = some_view # fullSyncFull, fullSyncGroups, fullSyncChangeFlag, incrementalAllColumns, incrementalPrimaryKey otherJob.some_view_incremental.syncType = incrementalAllColumns
Here is a sample log entry. Takes less than a second to update 100 records
2020-02-13 21:49:38,356: [main] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: true, state: done, sync: sqlTableSync, provisionerName: personSourceProd, syncType: incrementalAllColumns, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, lastRetrieved: 2020-02-13 21:31:14.739, incrementalChangesCount: 113, incrementalChangesMillis: 174, selectAllColumnsCount: 113, selectAllColumnsMillis: 54, deletesCount: 0, deletesMillis: 0, insertsCount: 0, insertsMillis: 0, updatesCount: 113, updatesMillis: 59, queryCount: 11, tookMillis: 920, took: 0:00:00.920
incrementalPrimaryKey
This is the more precise method for incremental SQL syncing since it will sync deletes as well as inserts and updates. This requires a separate table which has primary keys and a timestamp or sequential incrementing column. You can implement this with a SQL trigger pretty easily. Note, you should have a job that deletes old records from this table (e.g. more than a day old). Note: there is no column in the "changes table" for if it is an insert, update, or delete. Any records processed will be selected from the source and destination to make sure they are correct.
Example trigger (oracle). This uses a sequence for the change number, but could be a timestamp instead. A sequence is a better way to go since there will not be conflicts
CREATE OR REPLACE TRIGGER computed_person_chglog_trg
after INSERT OR UPDATE OR DELETE on computed_person
for each row
declare
employee_id number(8);
the_change_id integer;
begin
select audit_sequence.nextval into the_change_id from dual;
if (inserting) then
employee_id := :new.employee_id;
elsif (updating) then
employee_id := :new.employee_id;
--cant update the penn_id
if (:new.employee_id <> :old.employee_id) then
raise_application_error(-20123, 'Cannot change the employee_id of a row. You can delete and insert if you like');
end if;
elsif (deleting) then
employee_id := :old.employee_id;
end if;
insert into computed_person_chglog (id, last_edited, employee_id) values
(the_change_id, systimestamp, employee_id);
end;
/
In my case, my change log table has a numeric employee id, but my sync table has a text based employee id. i will need a view to convert those
create view some_view_chglog as select M.CHAR_employee_ID as employee_id, CPC.ID as incrementing_index from pcdadmin.computed_person_chglog cpc, comadmin.member m where CPC.employee_ID = M.employee_ID
grouper.client.properties
FIRST, REMOVE THE INCREMENTAL ALL COLUMNS CONFIG
****** grouperClient.syncTable.some_view.incrementalAllColumnsColumn *******
ADD THE TABLE AND COLUMN FOR CHANGES
# if querying a real time table, this is the table, needs to have primary key columns.
# each record will check the source and destination and see what to do
# {valueType: "string"}
grouperClient.syncTable.some_view.incrementalPrimaryKeyTable = some_view_chglog
# name of a column that has a sequence or last updated date.
# must be in the incrementalPrimaryKeyTable if incremental primary key sync
# {valueType: "string"}
grouperClient.syncTable.some_view.incrementalProgressColumn = incrementing_index
grouper-loader.properties
# fullSyncFull, fullSyncGroups, fullSyncChangeFlag, incrementalAllColumns, incrementalPrimaryKey otherJob.some_view_incremental.syncType = incrementalPrimaryKey
Since we are switching incremental types, from all columns to primary key table. So clear out progress
update grouper_sync set incremental_index = null, incremental_timestamp = null where provisioner_name = 'some_view'; commit; update grouper_sync_job gsj set last_sync_index = null where grouper_sync_id = (select id from grouper_sync gs where gs.provisioner_name = 'some_view'); commit;
Run a full sync to make sure the incremental progress is reset
Now see the max incremental progress:
select max( svc.incrementing_index ) from some_view_chglog svc
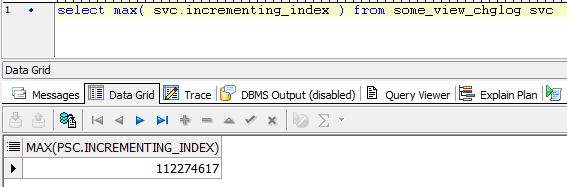
This should be approximately the current index (depending on how much time has passed and how many records updated in the meantime...
select id, provisioner_name, incremental_index, incremental_timestamp from grouper_sync where provisioner_name = 'some_view';

Kick it off and see how it does. Sample log:
2020-02-14 02:11:34,831: [main] DEBUG GcTableSyncLog.debugLog(33) - - finalLog: true, state: done, sync: sqlTableSync, provisionerName: personSourceProd, syncType: incrementalPrimaryKey, databaseFrom: pcom, tableFrom: PERSON_SOURCE2_v, databaseTo: awsProd, tableTo: PERSON_SOURCE, tableIncremental: person_source_chglog, lastRetrieved: 112279636, incrementalChangesCount: 12, incrementalChangesMillis: 14, selectAllColumnsCount: 24, selectAllColumnsMillis: 36, deletesCount: 0, deletesMillis: 0, insertsCount: 0, insertsMillis: 0, updatesCount: 12, updatesMillis: 25, queryCount: 12, tookMillis: 848, took: 0:00:00.848